Nodes in Pega Cluster – Understanding

In this blog article, we will see some basics about Clusters and Nodes
What is a cluster?
– A cluster is a group of servers and resources that work together.
– Just for logical reason, you can map a cluster with the system name, we saw in the previous post.
Think of the Pega Personal edition. Installing Pega package refers to installing the source code into database system. For Personal edition we use the relational database – Postgres. You can see the source code available in multiple tables in the rule schema.
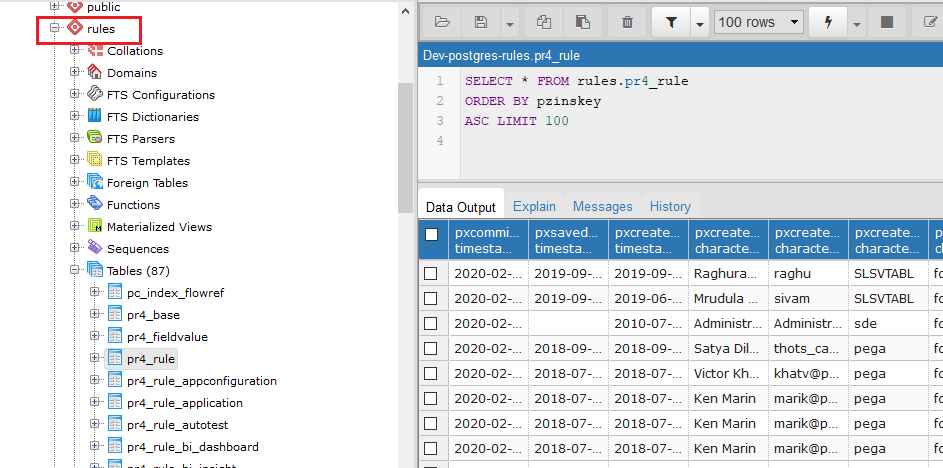
For Personal edition, we have a single Apache Tomcat webserver running over the Postgres database. You know in the server context.xml and prconfig.xml files, you specified the database driver to connect to the Postgres database.
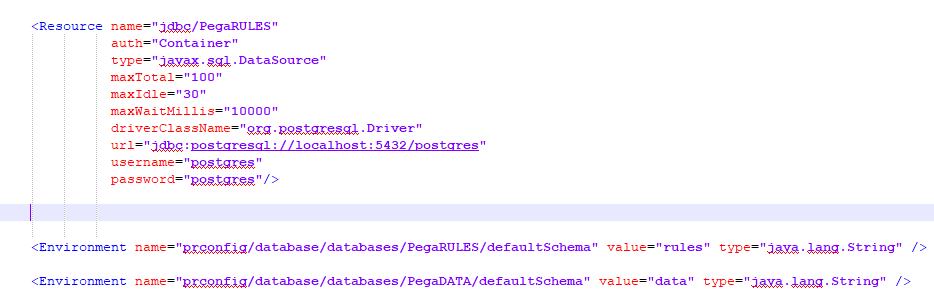
So currently we have a single Apache server, we can call the server as a node. So a single active node is available. Do we have a cluster? – The answer is yes. There is a cluster with a single node.
Is it possible to have more than one Apache Tomcat web server run on the Postgres database? – Yes, it is totally possible :). We can always have more than one node in a cluster.
Enjoying this content?
Access the author’s full video courses here at MyKnowAcademy.
Explore Courses →
That explains what is cluster!
What are the benefits of clustering?
1. High availability
Especially in a production environment, High availability is the main requirement for any application. Imagine a production application running on a single server(node). What will happen if the server crashes? – Unless proper action is taken, your application will be not available!! But if we have two or more servers running the application, then we can kind of accept having one server down, because the other servers still run the application.
2. Resource allocation
If we have more than one server running for an application, we can effectively allocate the resources (running processes) and share the work load across servers.
Node classification helps in achieving this benefit. We will talk about it in the next article.
3. Load balancing and increased performance
Load balancing refers to distributing the workload across servers. Also having multiple servers always improve the processing power and the performance.
4. Scalability
With clustering, it is always possible to add more servers to support scalability.
what is a node instance?
– Node instance is one on one mapping to the application server (node).
– Node is referred to as a data instance that belongs to category – SysAdmin.
– A system node instance is automatically created every time when a new server joins the system.
Let’s see the list of node instances available in the system.
Nodes are instances of class Data-Admin-Nodes.
Click on Records -> SysAdmin -> System Node
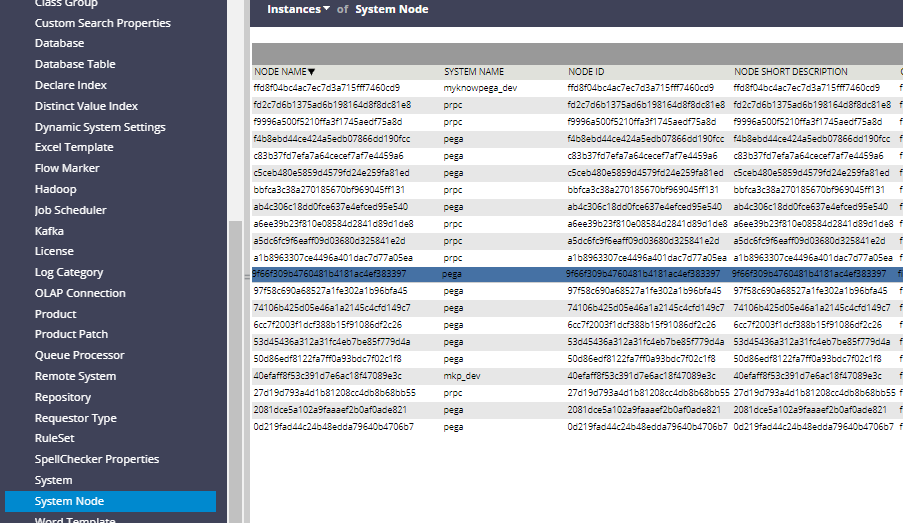
You will see the list of system nodes already available.
Important note: List of Data-Admin-Nodes instances do not mean all the nodes (servers) are running!! Most of the nodes may be already dead! Those are just instances J. There can be only few active nodes.
You can click and open the node name, that belongs to System Name = myknowpega_dev
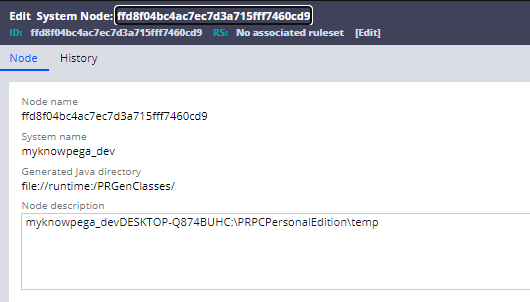
Node name = node ID.
Node ID is the 32-character auto-generated hash key. This is the unique ID that helps to uniquely identify the server.
How often this node ID is regenerated?
As per the documentation, Node ID generation is based on three parameters.
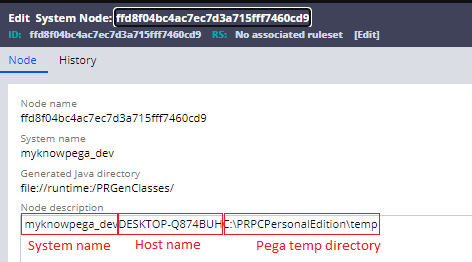
- Host name
- System name
- Pega temp directory.
When any one of the parameters changes then node ID will be re-generated. We saw in the previous post that whenever you change the system name, node ID is re-generated.
I will give a task. Change the temp directory location in the file C:PRPCPersonalEditiontomcatconfcontext.xml

Restart the server and verify the node ID regeneration.
How to check the current node ID?
1. On the System Name – landing page, you will see a list of active nodes.
Configure -> System -> Settings -> System name
2. You can see the node status in data schema table –
pr_sys_statusnodes
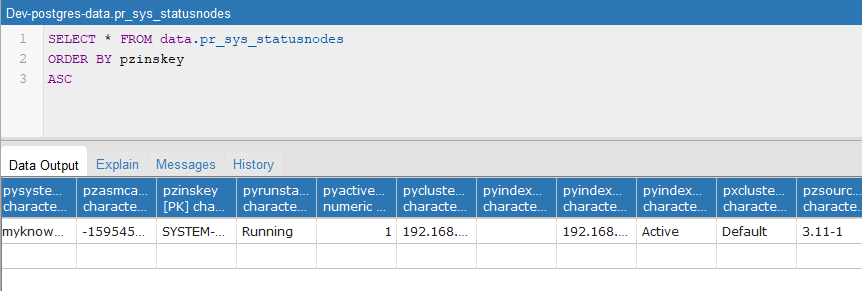
Pega engine and node cleaner agents automatically maintains this table.
You will see a lot of interesting details in the table – like status, IP address etc.
Note: There may be some situation where you may need to manually delete the instances before restarting server.
3. From the admin portal, you can verify the active node details
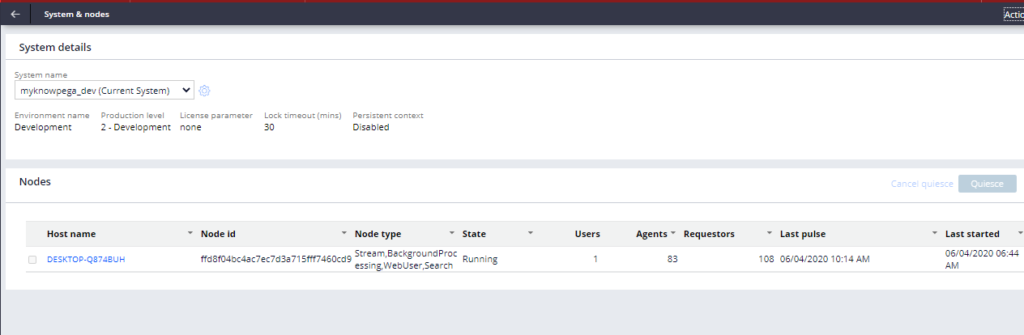
You can click on the Host name link, to check the node configuration details.
One interesting option you see is quiese button.
Quiesce
– Ability to gracefully take a server out of service for maintenance purpose.
– When you start quiesce, the users from the quiescing node will be moved to the other active nodes, so that the server can be taken down.
– Quiesce button will be enabled only when you have more than one active nodes.
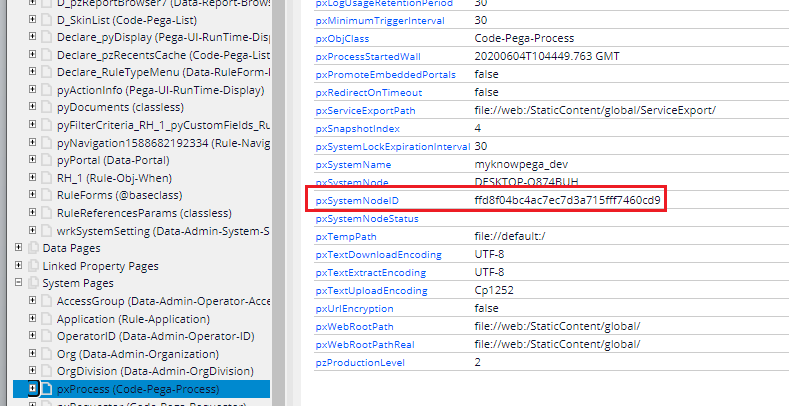
4. In the clipboard, you can find the node ID in the pxProcess page.
pxProcess.pxSystemNodeID
Okay, now imagine there are 3 active servers running.
We know that Pega uses different technologies / softwares like
Elastic search – search functionality
Kafka – Stream services for event processing
In production system , do you want to run these processes in the same server where Pega ends users login to access the application?
This is where node classification comes into picture. We can classify the server to run specific processes in specific servers. I will save the explanation in my next post.
As a summary,
– Node refers to server and in any system (dev, st, uat, prod), you can have one or more active servers(nodes).
– Each node is uniquely identified by auto-generated node ID.
– Node ID can re-generated when any one of the parameter – host name, system name, temp directory changes.
– Active nodes / current node can be viewed in different ways – pr_status_nodes table, System Name landing page, admin studio – system & nodes or in clipboard.



