Kafka – Part 1 – Fundamentals

Welcome to the first article on Kafka series. Here we will talk some theory concepts on Kafka fundamentals.
What is Kafka?
Kafka is a distributed streaming platform.
Stream here refers to stream of data. Imagine an organization has around 3 source systems and 4 target systems. Each system needs to communicate with each other to transfer the data between systems. If you think of achieving this using Web services like – SOAP or REST, then you may be need to define around 12 Integrations as shown below

This is where the messaging solution comes in!! In the previous posts on JMS series, we talked about messaging model – point-to point & publish and subscribe.
Here in the above use case, Publish and Subscribe can solve the problem, where the source system can just publish the messages to a messaging platform or a broker and the interested target systems can subscribe and receive the published messages.
In the below picture, you will see Kafka as a messaging broker, where different applications can produce messages (send) to Kafka broker and also different applications can consume the same messages.
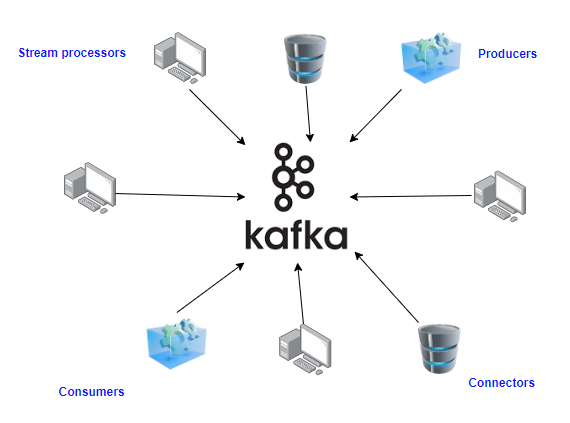
In the above picture, You see there are producers, consumers, connectors, Stream processors. What are they?
Enjoying this content?
Access the author’s full video courses here at MyKnowAcademy.
Explore Courses →
These are the core Java APIs in Kafka.
- Producer API
- Consumer API
- Streams API
- Connector API
When Kafka was introduced, it came up with two simple Java APIs – Producer and Consumer. In later point of time, many contributed to build new APIs like Streams, Connector that is built over Producer and Consumer APIs.
Producer API – Set of library that allows an application to send streams of data to one or more topics.
Consumer API – Set of library that supports reading streams of data and perform action on it.
Streams API – Streams API Library is built on top of Producer and Consumer API. Streams API are mostly used in real time event processing. Pega engine, uses this streams API to process the real time data (Queue processors uses this Kafka Stream API).
Kafka streams API can both read the stream data and as well as publish the data to Kafka. It is one of most powerful API that is getting embraced many many organizations.
Connector API – There are two types
a) Kafka Connect Source API – This API is built over producer API, which bridges the application like databases to connect to Kafka.
b) Kafka Connect Sink API – This API is built over consumer API, which can read stream of data from Kafka and store it in other applications or databases.
I would suggest you go through the below link for more details on Kafka API
Kafka architecture terminologies
Topic, Partitions and Offset–
Topic
Topic is a name to group the Kafka messages.
Think of a database, where you can use tables to store set of related data. Similarly in Kafka, the storage part is named as Topic.
Note: We already saw the term Topic in publish and subscribe model.
You can have ‘n’ number of Topics
Partitions
Topics are split into partitions.
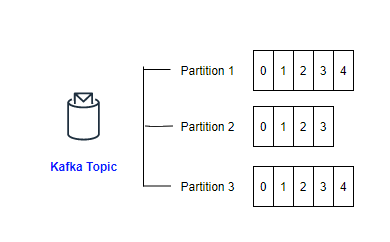
When defining a topic, you can always specify how many partitions you need.
In the above picture, you see there are 3 partitions defined for the kafka topic and 14 messages written into the Kafka topic and stored equally in 3 partitions.
Offset
Each message within the partition gets an incremental ID called offset.
Partition 1 hold 5 messages, Partition 2 – 4 messages and Partition 3 – 5 messages.
You may get a question, what is the order of messages?
Offset order is guaranteed only within the partition.
It means in Partition 2, Offset 1 message may be sent before Offset 0 in Partition 1. The offset are immutable and keeps on increasing!
– Offset has meaning only within the partition.
As I said the 14 messages in the topic are split into 3 partitions. So offset 1 in partition 1 and offset 1 in partition 2 are not the same message.
Data in a topic is kept only for a limited time. By default, the data is kept for 1 week, but can configured to store for long.
Important note: Even when the message is removed from the queue, the offset do not reset. It just keeps on incrementing.
Let’s see a real-time example.
Uber is the real-time usecase for Kafka. Uber uses Kafka to track their cars.
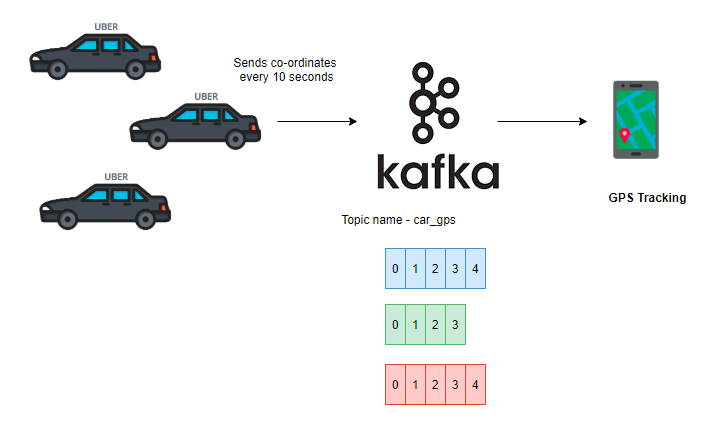
Each Uber car sends their latitude longitude co-ordinates to Kafka topic, say– car_gps.
Car_gps topic is configured with 3 partitions.
Here Uber car acts as a producer and sends the message to Kafka topic and GPS Tracking application act as consumer to consume the messages and display them in a nice dashboard.
You may get a question, how do we ensure that messages are in order?
For example, say at 10:00:00, Car A sends its location to Kafka topic. The message sits on Offset 5 in partition 1. After 10 seconds at 10:00:10, Car A sends its new location to the Kafka topic. Where do the message go? Partition 1?
We know that offset ordering is only applicable within a partition. So ideally all messages (locations) from Car A should always go to same partition, so that order is maintained correctly to display in the dashboard.
How the data gets assigned to a partition?
Two simple rules.
- Data is assigned randomly to a partition unless a message key is provided. (round-robin assignment)
- Message keys – message keys determine to which partition a message should be assigned.
Message keys –
– Producers can send a key with the message.
– If a key is sent, all messages with the key will always be assigned to the same partition.
In our Uber car example, we can say – Car_ID as the message key.
So producers when they send their location, they also send their Car_ID as key. Kafka internally make sure that all messages from the same Car_ID always go into the same partition. Hence the message order is maintained 🙂
Till now we talked about – topics, partitions, offset and message key.
Where do these topics get stored?
First I will talk about a term – Fault tolerance.
Mostly all the Organizations have their own data centers.
What is a data centre?
– Can be a building or a dedicated space in a building which house a group of computer servers for storage or processing large amounts of data.
– Usuall,y there will be two or more data centres that are separated by certain geo location. So if there is some kind of power failure or natural disaster in one data center, there will always be another one alive to serve the purpose.
– In a data centre you can have multiple servers separated in separate racks.
Fault tolerance – It enables a system to operate continuously in the event of failure of some of its components.
In the Kafka definition, we saw Kafka as a distributed streaming platform.
Distributed here refers to data getting distributed to multiple servers (brokers) so that it provides fault tolerance in case of server goes down!
In Kafka, sthe erver refers to brokers.
– Brokers hold the topics and partitions.
What is a broker?
We already discussed about the cluster–server topology in the previous articles. A Kafka cluster consists of one or more brokers.
Every kafka broker is all called a bootstrap server.
It means to connect to a Kafka cluster all you need to is connect to one broker. This is because each Kafka broker holds the metadata about all brokers, topics and partitions.
So when a Kafka client connects to a broker, broker discovery happens internally and the client connects to the cluster seamlessly!
– Each broker is identified by a unique broker ID.
– Each broker stores certain topic partitions
Important note: Since Kafka is a distributed system, not all brokers store the entire kafka data (or partitions).
Let’s say, there are 3 brokers in a Kafka cluster – Broker 1, Broker 2, Broker 3.
2 Topics – Topic A, Topic B configured with 3 Partitions.
You see the topics and partitions are evenly distributed across brokers.
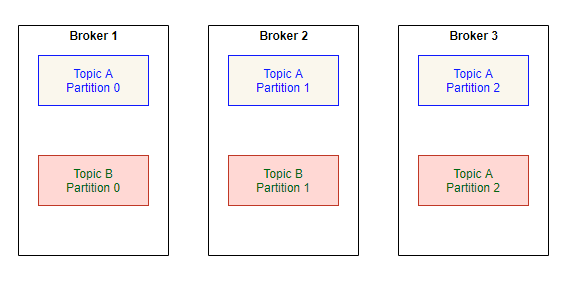
What happens if the broker 2 goes down????
Replication factor –
In a distributed system, you always need to have some data replication, so that even when one server goes down, data will not be lost.
While creating a new topic, in addition to specifying number of partitions, you can also specify the number of replication factor.
The ideal situation, you can have a replication factor as 2 or 3.
Let’s see how the data gets distributed if you specify the replication factor as 2.
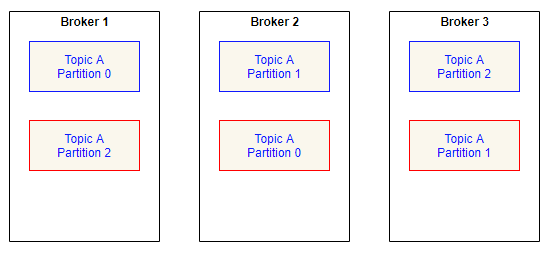
Each topic partition is replicated twice in two brokers.
You see Topic A Partition 0 is replicated in Broker 1 and Broker 2.
Now assume, Broker 2 is down for any technical reason, still Broker 1 and broker 3 stores all the partition data in their machine and hence data is not lost.
Now we have replicas of data in different brokers. From which broker, can the consumer consumes the data for Topic A Partition 0 – Broker 1 or Broker 2?
Leader of a Partition –
Kafka maintains the concept of a leader for each partition.
– At any point of time, there can be only one broker act as a leader for any given partition.
– The leader receives the data and serves the data.
– Other brokers just synchronize the data for replication. The other brokers that sync the data are called in-sync-replica (ISR).
The leader election is taken care of by Zookeeper.
Let’s say for Topic A Partition 1 – Broker 1 is the leader and Broker 2 is the ISR. When Broker 1, the leader goes down, then Zookeeper will take care of performing the leader election and make the ISR the temporary leader. When Broker 1 comes up, it will automatically take up the leader position. We don’t need to care about these things; all are taken care of internally by Kafka 🙂
So, what is Zookeeper now?
It is another software developed by Apache that acts as a centralized service to manage the distributed Kafka systems.
Kafka and Zookeeper are life partners 😉 Kafka cannot work without Zookeeper.
Managing distributed Kafka brokers
– Zookeeper keeps a list of brokers in the Kafka cluster.
– As we saw before, Zookeeper helps in performing leader election for partitions.
– Whenever a new topic created, topic deleted, broker dies or comes up, Zookeeper tells Kafka about it.
Zookeeper also have their cluster with a leader and followers.
Zookeeper cluster connects to Kafka cluster!
Okay, now final two theory topics
Producers and Consumers
What is a Producer in Kafka?
– Producer writes data to topics.
– Producers connect to a single Kafka broker and then using broker discovery they automatically know to which broker and partition they need to write data to
– Producer can choose to receive acknowledgement for data writes.
There are three possible ways of data acknowledgement.
a. Acks = 0 – Producer do not wait for acknowledgement. This can lead to possible data loss, because at the time of message sending, if the broker is down, broker won’t know about it!!
b. Acks = 1 – Producer waits for leader acknowledgement. This can limit data loss, because at the time of message sending the ISRs can be down and hence the message cannot be synced.
c. Acks = all – Producer waits for leader + ISRs acknowledgement. No data loss.
What is a consumer in Kafka?
– Consumer reads data from topics.
– Consumers connect to a single Kafka broker and then using broker discovery they automatically know to which broker and partition they need to read data.
– Data is always read from Partitions in order.
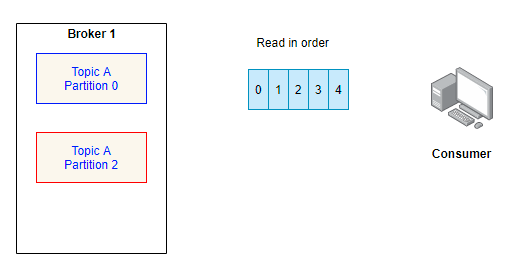
Okay, now a question. Does consumer map one on one with Consuming application?
NO. There is another term called Consumer groups.
Consumers read data in consumer groups
Let’s say there is a topic A with two partitions. There are two consuming applications that are interested in the messages in topic A.
Each consuming application forms a consumer group.
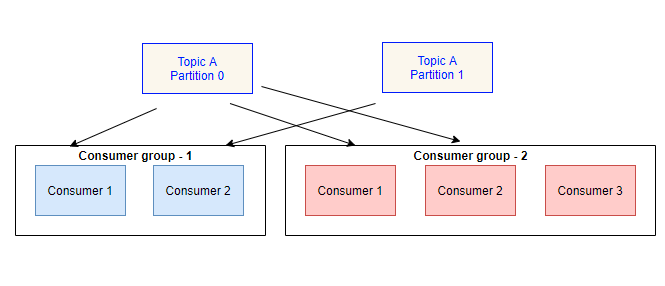
You see above that each consumer from a consumer group reads from specific partitions.
If consumers are greater than the no of partitions then the consumer can be inactive.
Again assigning a consumer to partitions is taken care internally by Kafka and we don’t need to worry about it.
We saw that Kafka messages are ordered in offsets in a partitions.
Say a consumer reads the message from a partition 0 till offset 5. Now the consumer is taken down for maintenance purposes. When the consumer comes back live, from where it should read the message. The ideal situation will be, consumers should read after offset 5.
What is consumer offsets?
– Kafka internally stores the offsets at which the consumer group is reading.
– The offsets are committed in a Kafka topic _consumer_offsets.
– Whenever a consumer in a group processes the data, then it should commit the offsets.
Consumers can choose when to commit the offsets.
There are three delivery semantics
a. At most once – Offsets are committed as soon as the message is read. If the message processing goes wrong, then it is lost forever and never read again.
b. At least once – this is the preferred approach. Offsets are committed only when the message is processed.
Note: Make sure you use idempotent syntax in processing, because there is a chance of duplicate message (or processing same message twice)
c. Exactly once – This is applicable only for Kafka to Kafka workflows using Kafka streams API.
Finally we are at the end of Kafka theory topics.
I know it may be heavy initially, but please read about it and understand the theoretical concepts well before jumping into tutorials. There are a lot of good articles surfing around, do browse and understand the concepts fully.



