Standard Queue Processing Vs Dedicated Queue Processing in Pega

When it comes to background processing in Pega, one design question shows up again and again.
should I just reuse the standard queue processor, or should I create a dedicated one?
On paper, both may look similar. After all, both are queue processors, both work in the same architecture, and both can execute background work. But in real projects, this is not a small technical choice. It is a design decision that can directly affect scalability, flexibility, and even operational stability.
And this is exactly where many teams get it wrong.
They see that pzStandardProcessor can execute their activity, and immediately conclude that it should be good enough. Technically possible? Yes. Good design choice? Not always.
In this article, let us break that confusion and understand when it makes sense to go with standard queue processing and when it is clearly better to create a dedicated queue processor.
What is common between them?
Before looking at the differences, let us first clear one common misconception.
Both standard queue processors and dedicated queue processors are built on the same backend foundations. Both use a Kafka topic and a data flow for processing. So from a platform architecture standpoint, they are not two completely different worlds.
Enjoying this content?
Access the author’s full video courses here at MyKnowAcademy.
Explore Courses →
In simple words, every queue processor, whether standard or dedicated gets its own backend processing path involving Kafka and data flow.
I already explained the relationship between queue processors, Kafka topics, and data flows in detail in one of my YouTube videos.
So the real question is not about whether they use different technology underneath. The real question is about how you should design for your requirement.
Understanding pzStandardProcessor
Standard queue processors are the ones that come out of the box with the Pega platform. You will see several of them, such as pyProcessNotification and pzStandardProcessor.
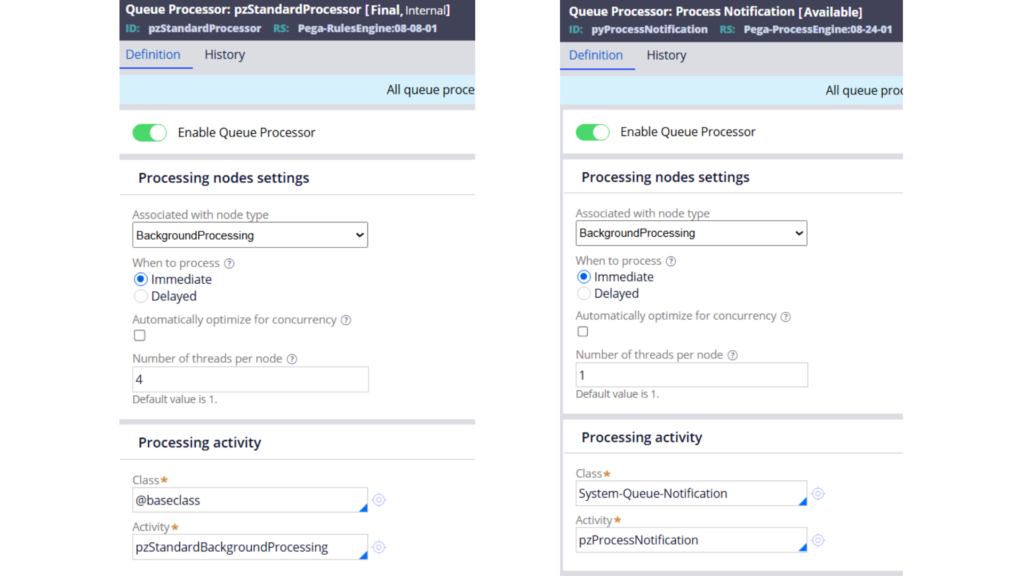
For this discussion, let us mainly focus on pzStandardProcessor, because that is usually the processor people are tempted to reuse.
If you inspect the rule, you will notice a few important things. It is a final rule.
It comes with predefined behavior. It uses a generic background activity such as pzStandardBackgroundProcessing. And if you trace the execution further, you will notice that the actual activity to be executed is dynamically picked up from the pyQueuePage.
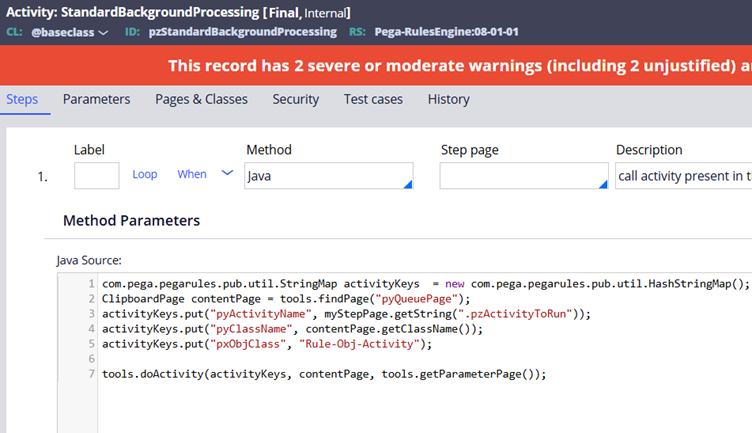
That is the part that makes it attractive.
Because of that behavior, you can reuse pzStandardProcessor to execute your own activity by using Queue-For-Processing and selecting the queue type as Standard.
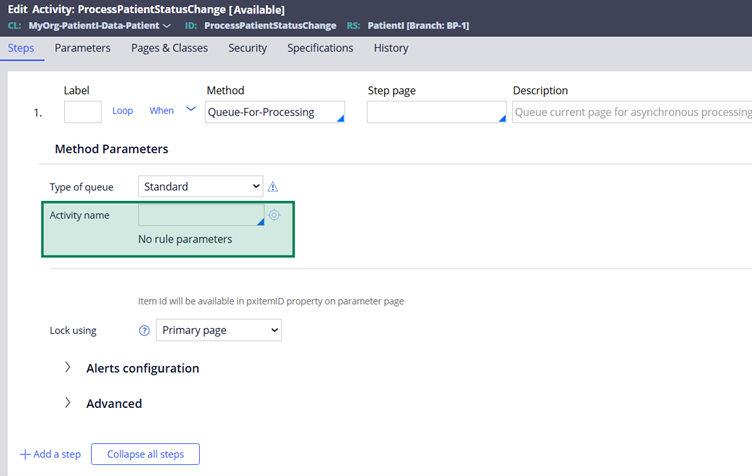
So yes, it is convenient.
But let us be honest, convenience is one of the most dangerous reasons to make an architectural decision.
What is a dedicated queue processor?
A dedicated queue processor is nothing fancy. It is simply a queue processor rule that you create specifically for your own business requirement.
Instead of pushing your background work into pzStandardProcessor, you define your own queue processor and use it for that use case alone.
That gives you what the standard processor does not naturally give you – better isolation, better control, and a cleaner design boundary.
So from here onward, the comparison is really between reusing pzStandardProcessor versus creating your own dedicated queue processor.
The first clear difference: immediate vs delayed processing
Let us start with the easiest design differentiator.
pzStandardProcessor is generally immediate in nature. Once Queue-For-Processing is invoked, the item is pushed for processing and gets picked up almost in real time.
A dedicated queue processor gives you more freedom. You can choose whether the processing should happen immediately or in a delayed manner.
That already gives us the first simple rule:
If the requirement needs delayed processing, do not overthink it. Go with a dedicated queue processor.
This is one of those decisions that is almost automatic. The standard processor is simply not the right fit for that kind of requirement.
Why reusing the standard processor is not always smart
Now let us come to the real design discussion.
A lot of developers look at pzStandardProcessor and think: If Pega already gives me this, why should I create another queue processor rule?
The problem with that thinking is simple – pzStandardProcessor is shared processing capacity.
It is not sitting there waiting only for your use case. Pega itself uses standard queue processors for out-of-the-box background work. For example, in Infinity ’25, even SLA processing uses standard queue processing.
Now think about what that means in practice.
The moment you start pushing your own heavy or high-volume business processing into the same shared processor, you are no longer just using a handy utility. You are stepping into a shared execution lane that may already be serving important platform workloads.
That is where the real risk starts.
So this is not merely a question of “Can I use the standard processor?”
It is a more serious question of “Should I allow my business workload to compete with shared platform processing?”
That is a very different conversation.
When standard queue processing is a reasonable choice
Now let us be practical. This does not mean standard queue processing is bad. It absolutely has its place.
It is usually a reasonable choice in the following situations:
1. When the processing is simple and lightweight
If the background task is straightforward, short, and does not involve heavy logic, the standard queue processor is often perfectly fine. There is no need to create extra design complexity for a tiny use case.
2. When the volume is low
If you are dealing with a small number of queued items and the throughput expectation is modest, reusing the standard queue processor can be a practical and efficient option.
3. When the processing is not business critical
If the task is useful but not operationally sensitive, using a shared processor is generally acceptable. In other words, if slight contention is not going to hurt the business, standard processing may be enough.
4. When you want quick implementation for a small use case
For one-time actions or lightweight asynchronous tasks, the standard queue processor offers a convenient option without the overhead of introducing and managing a separate queue processor rule.
This is where standard queue processing fits nicely small, simple, low-risk work.
When dedicated queue processing is the safer choice
This is where I become a bit opinionated.
The moment the requirement becomes serious, the safer choice is usually a dedicated queue processor. Not sometimes. In most real-world design situations, that is the better decision.
A dedicated queue processor becomes the right choice in the following situations:
1. When the processing is high volume or mission-critical
If the background work is heavy, frequent, or important to business operations, isolating it is just good design. Pushing it into a shared standard processor is asking for unnecessary contention.
2. When delayed processing is required
If the use case needs delayed execution, the decision is straightforward. Use a dedicated queue processor. pzStandardProcessor is not designed to give you that kind of flexibility.
3. When the activity is long running or performance sensitive
Long-running background work should not casually sit in a shared processor that may already be used by other workloads. If the process takes time or needs more predictable behavior, dedicated queue processing is the safer path.
4. When you need better control over processing behavior
Since pzStandardProcessor is a final rule, your flexibility is naturally limited. With a dedicated queue processor, you get a much cleaner model for tuning and managing processing behavior for more serious workloads.
And honestly, this is the part many teams underestimate.
They treat all queue processing needs as equal. They are not.
A lightweight async notification and a high-volume business process should not automatically be treated as if they deserve the same processing strategy.
A practical way to decide
If you want a simple mental shortcut, here it is.
Use the standard queue processor when the background work is small, low volume, lightweight, and not particularly important from a business operations standpoint.
Use a dedicated queue processor when the work is heavy, delayed, long-running, mission-critical, or important enough that you do not want it competing with shared platform jobs.
That is really the heart of the decision.
And if you are ever in doubt, I would rather lean slightly toward a dedicated queue processor for an important use case than casually throw it into pzStandardProcessor just because it is available.
Because in architecture, shared convenience today can become shared pain tomorrow.
Final thoughts
From a pure implementation viewpoint, both standard and dedicated queue processors are built on the same backend concepts of Kafka topics and data flows. But from a design viewpoint, they should never be treated as interchangeable by default.
pzStandardProcessor is useful. No doubt about that. But it is useful mainly for smaller, simpler, lower-risk background tasks.
The moment the requirement demands isolation, delayed execution, better control, or more predictable behavior, a dedicated queue processor stops being an optional extra and starts becoming the cleaner design choice.
So if I have to put the whole article into one practical takeaway, it would be this:
Use the standard queue processor for small and simple background tasks.
Use a dedicated queue processor for serious background processing.
That is usually the safer design. And in most enterprise systems, safer design wins.