Kafka – Part 7 – Pega Consumes the External Kafka Messages

In the previous blog article, we saw how we can make a connection between Pega and an external Kafka server. It is recommended to visit the Kafka articles in order for a better understanding.
https://myknowtech.com/tag/kafka
In this blog article, we will see how Pega can consume the Kafka messages published in the external Kafka server.
This tutorial is implemented using Pega personal edition 8.4, but the core concepts remain the same in higher versions as well
It is recommended to complete the pre-requisites from the External Kafka server setup blog article.
Business scenario: A banking organization ABC uses Pega Infinity to facilitate their sales process. Whenever a loan is issued, loan details are captured in a Java application that maintains the loan life cycle. Pega application is used to service customers who fail to pay the loan amount. The service case stores the loan details.
Business problem
Whenever a loan is fully settled, the loan status is updated in the golden source system (Java application) but the changes need to be propagated to all systems that use the loan status to make them up-to-date.
Solution
Kafka is chosen as the messaging platform. Whenever any loan expires, the Java application produces loan status message in a dedicated topic. Pega application is registered as one of the consumer and consumes the loan status change messages.
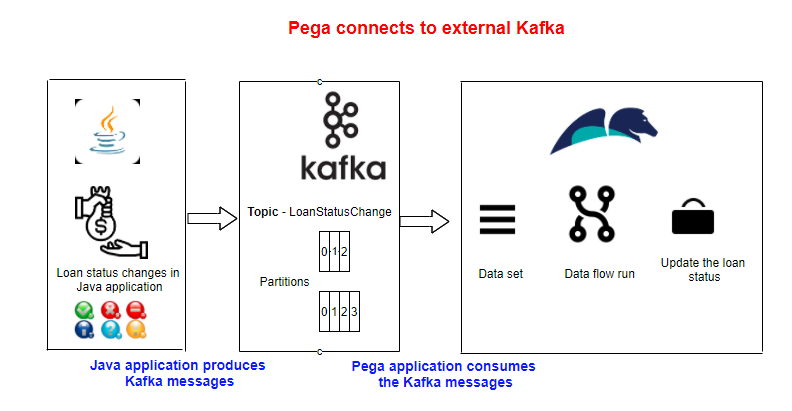
In this tutorial, we will see how this can be achieved using the data-set and data flow rules.
Mandatory pre-requisite –
Enjoying this content?
Access the author’s full video courses here at MyKnowAcademy.
Explore Courses →
1. Please follow the below post to make a connection between Pega and the External Kafka server.
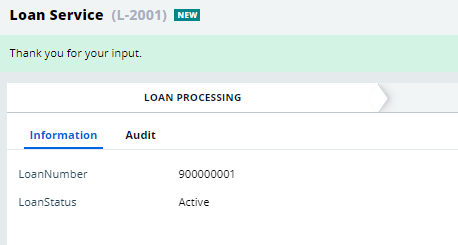
2. A service case is created with the loan number and status active.
3. Create a new topic – loanstatuschange in the Kafka server using the below command.
kafka-topics –create –zookeeper 127.0.0.1:2181 –topic myknowpega_first –partitions 5 –replication-factor 1

Okay pre-requisites are ready.
Configure Kafka data set in Pega
Step 1: Create the data model for your Kafka Integration.
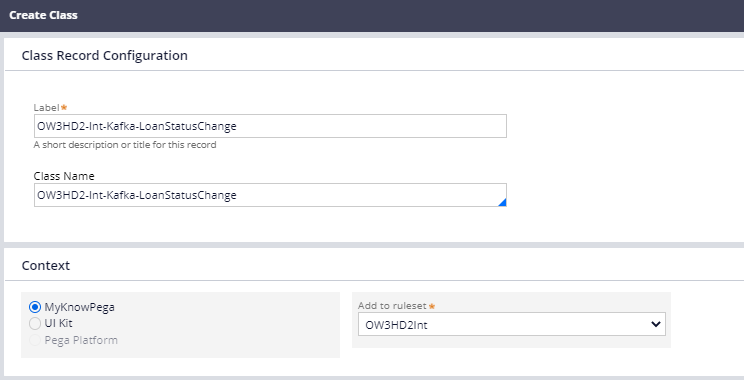
Step 1.1: Create an Integration class in the Ent Layer
<Org>-Int-Kafka-<TopicName>
OW3HD2-Int-Kafka-LoanStatusChange
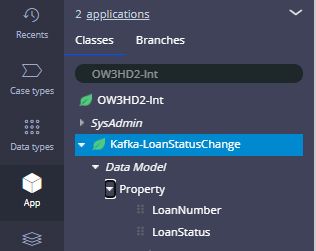
Step 1.2: Create two single value properties for Loan number and loan status.
Step 2: Create a new Kafka data set rule – LoanStatusChange.
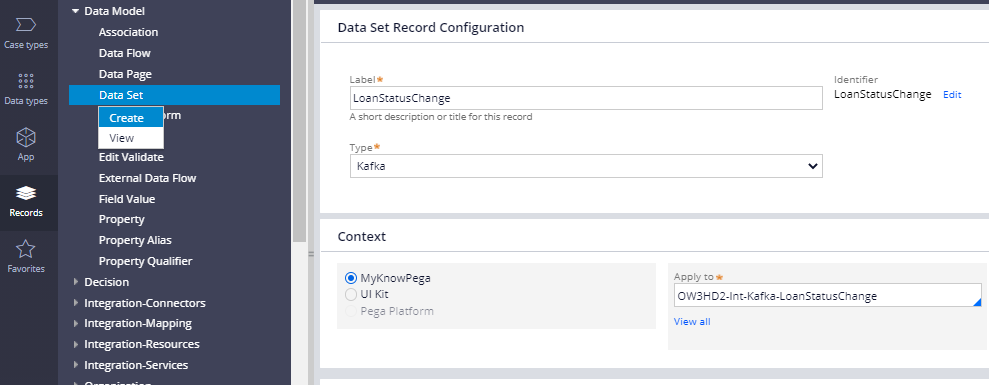
What are the configuration points in a Kafka data set rule?
There is a single main tab – Kafka, where you do all the main configurations.
Connections –
Here you can select the right Kafka instance rule (which we created in the previous post to make a connection between Pega and Kafka).
In our case, we created an instance – LocalKafka
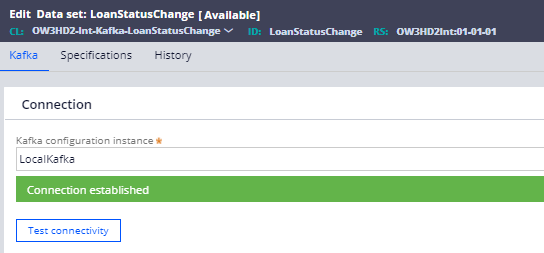
You can do a test connectivity to verify the connection.
Topic –
Here you can either create a new topic or select any existing topic. In our scenario, we need to consume the messages from existing topic. So you can select the already created topic from picklist.
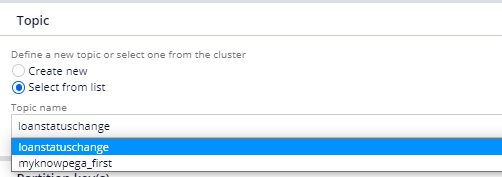
You see since the connection is made, Pega can automatically fetch you all the list of topics in the connected Kafka server.
Partition key(s) –
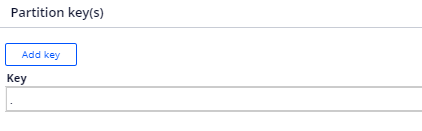
In the Kafka introduction posts, we saw the importance of Partition keys. We know that each Kafka topic can have one or more partitions to store the messages and the message ordering is guaranteed only within each partition.
If you have such use case where your ordering plays a critical role, for example: tracking your cab, you must specify a key, say – cabID, so that all messages for the same cab go to the same partition, so the geolocation ordering is maintained for the cab.
We will use partition keys in my next post where we produce Kafka messages 😉
Record format –
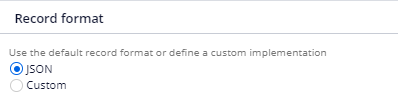
Here we have JSON as the default format and also we have an option to use custom format.
Based on the format, serialization and deserialization occur.
You can look at the below links for custom serde(serialization and deserialization) implementation
https://collaborate.pega.com/discussion/kafka-custom-serializerdeserializer-implementation
Here in our use case, we will keep it simple and use JSON format.
Save the data set rule.
Let’s run the data set rule and see if any messages are present in the topic.
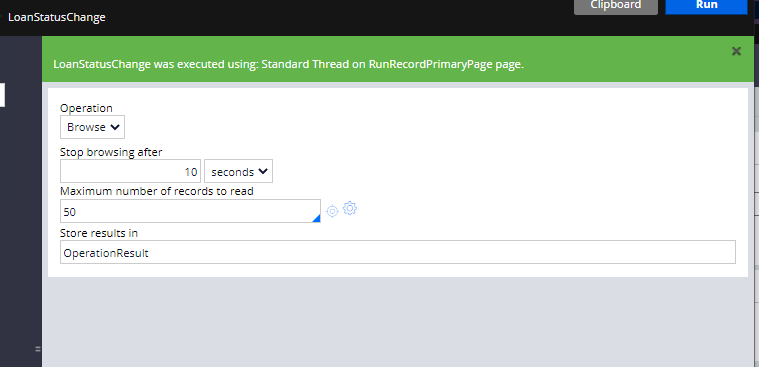
As expected, currently there are no messages in the loanstatuschange topic.
Now let’s produce a message in the topic from the producer console and check it back from the data set rule.
Open command prompt use the below command
kafka-console-producer –bootstrap-server 127.0.0.1:9093 –topic loanstatuschange

You will get a carrot sign, enter a valid JSON
{“LoanNumber”:”900000001″,”Loanstatus”:”Inactive”}
Now get back to the data set rule and run the rule.
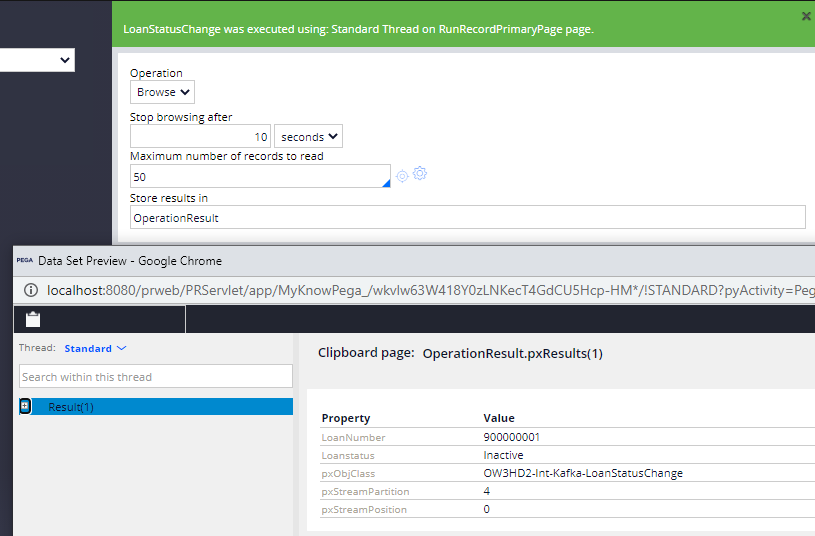
There you see the message retrieved from our data set rule.
Now the last step, configure the data flow rule to process the messages in real time.
Step 1: Create a new data flow rule.
Records -> Data Model -> Data Flow -> Create new
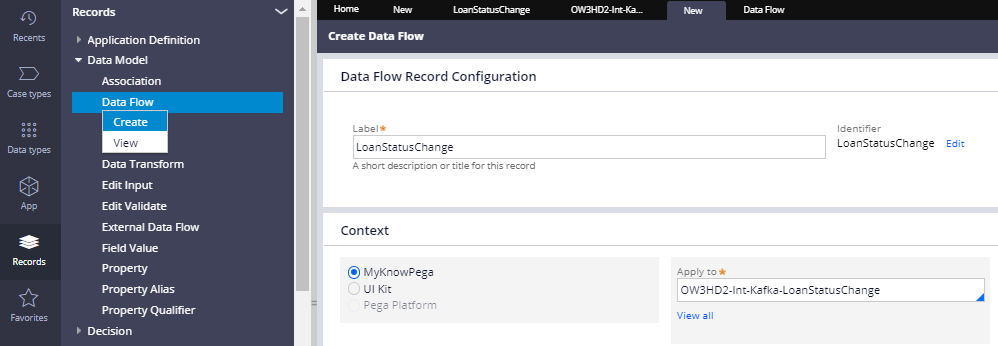
Step 2: Configure the source.
Use the Kafka data set as input.
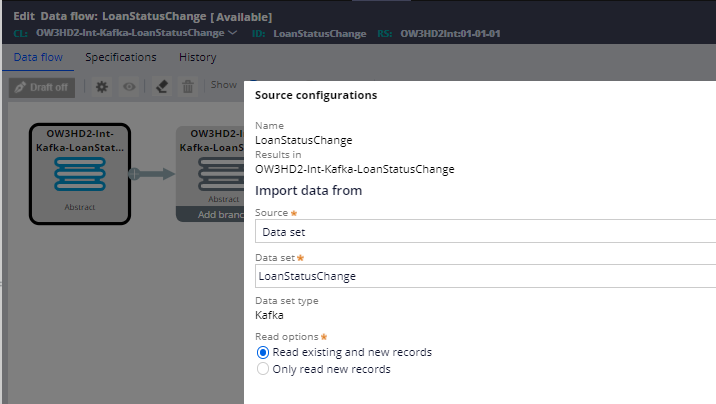
In Read options, you can decide whether to read all the existing messages and new records or only new records.
Since the messages were produced before my data flow run, I am going to use Read existing and new records.
Step 3: Create an output activity that can update the loan status in service cases by browsing cases based on loan number.
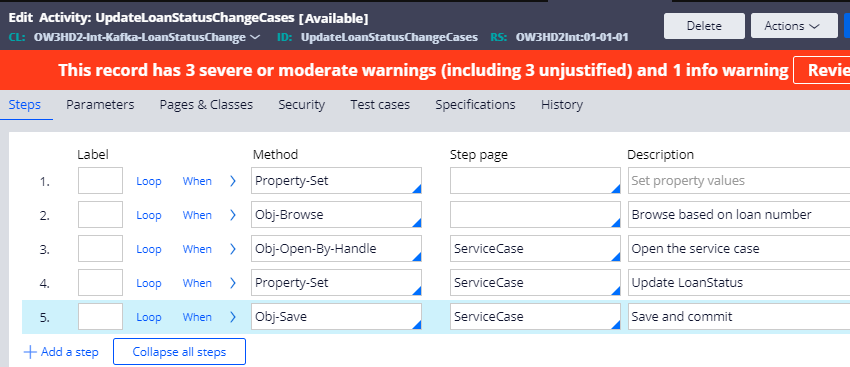
(for tutorial purposes, I didn’t follow the standard to add any error handling)
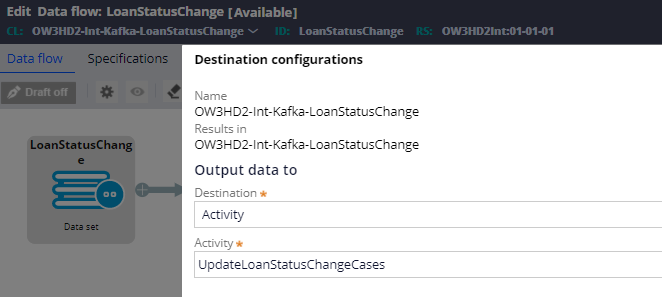
Step 4: Use the activity in the output shape of the data flow rule.
So, here is my simple data flow rule for consuming the loanstatuschange event.
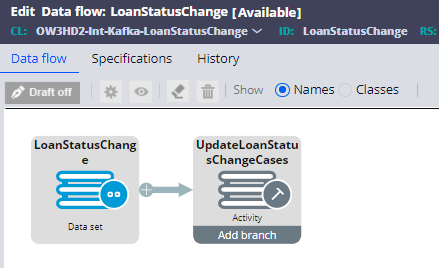
In real time you may need to use other shapes like filtering, enrichment shapes for further processing on the messages.
Finally, let’s start the real-time data flow.
Switch to Decisioning ->. Infrastructure -> Services -> Data flow
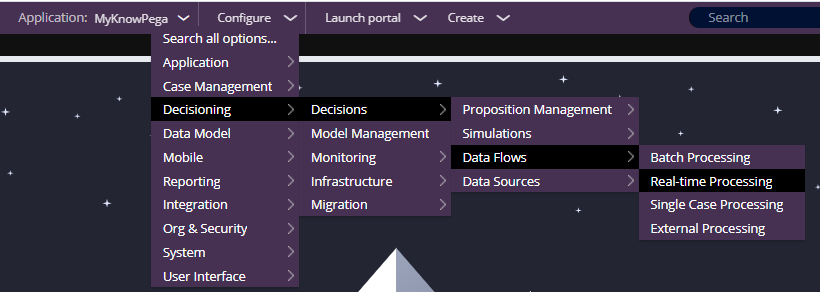
Click new to create a new data flow run.
I am going to tag the data flow run with the current background processing node type.
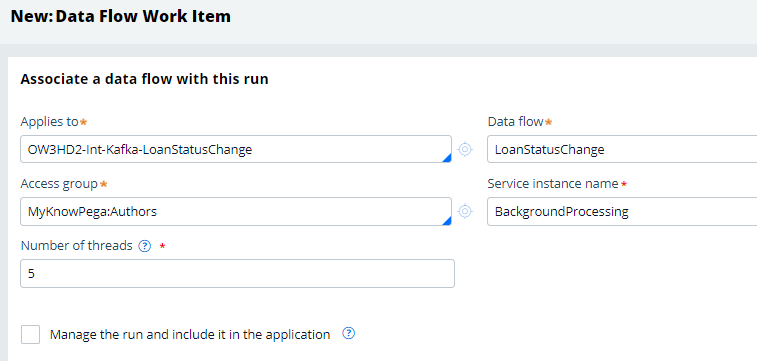
Once you are done with the configuration, click run.
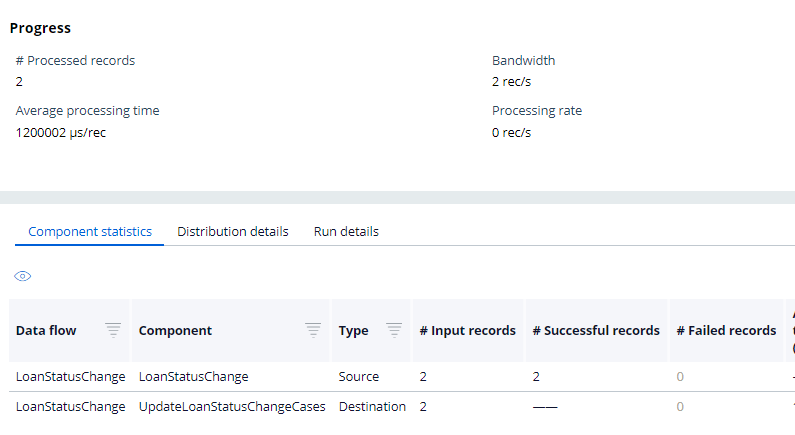
Important note: My first message is not processed correctly, because the message I produced is Loanstatus (s is small), but the mapping I made is LoanStatus :). I corrected the message with the right LoanStatus and now the second message correctly updated the service case.
I see case is updated with loan status Inactive.
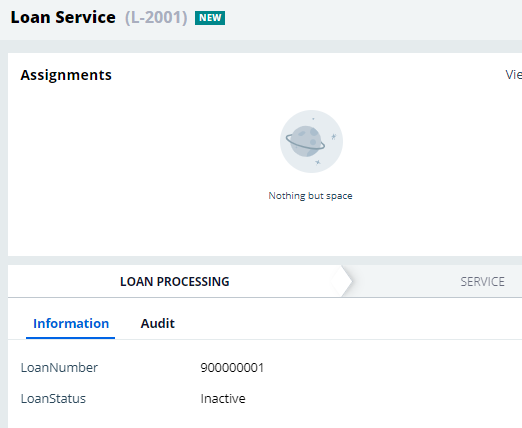
Let’s put another message now.
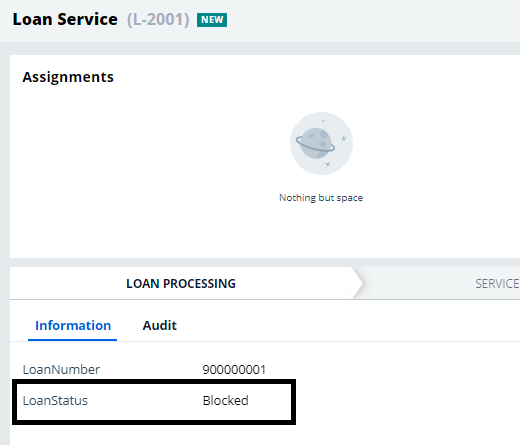
{“LoanNumber”:”900000001″,”LoanStatus”:”Blocked”}

And you see the case gets updated to status blocked.
Okay, we have successfully consumed and processed the published messages from the external Kafka server.
The final topic before ending this article… we used the JSON format message. But what if some extra key-value pairs are added to the message structure, how it can be maintained securely and validated?
We can use the Schema registry.
What is Schema registry?
– The name implies that it is a central place or repository to store the schemas so that producers and consumers can collaborate well on the message structure or the schema versions. It provides RESTful interface for the users.
The main advantages of having schema registry are
– Centralized registry
– Schema validation – security is added and messaged tempering is avoided. It provides a direct interface between brokers and schema registry for validation. It can be configured at the topic level.
– Version management – schemas can have different versions with different message structure changes.
I recommend you go through the below links to get better understanding on schema registry.
There are some future works going on to implement a new rule instance ‘Schema registry’ to make a connection from pega to schema registry server
https://github.com/pegasystems/dataset-integrations/releases/tag/1.0.0
In the next article, we will see how Pega can produce Kafka messages to an external Kafka server –



