Kafka – Part 5 – Data flows in Pega

In this blog article, we will make use of data sets we created in the previous post and we will also verify how data flows can be used in Pega to process source data.
This tutorial is implemented using Pega personal edition 8.4, but the core concepts remain the same in higher versions as well
It is recommended to go through previous blog articles on Kafka fundamentals before proceeding here.
https://myknowtech.com/tag/kafka
What is a data flow rule?
– A flow rule always has a start and an end. Similarly data flow rule allows you to combine the data from various sources (start) and write the results to a destination (end).
– Data flow is a rule instance that belongs to category – Data model and of applies to class Rule-Decision-DDF (Decision Data Flow)
– Data flow rule can make use of data set as input.
Data flows can be categorized into two types based on the source data set category type.
Enjoying this content?
Access the author’s full video courses here at MyKnowAcademy.
Explore Courses →
a) Stream data set – real-time data flow processing uses stream data set as input
b) Non Stream data set – batch flow processing that uses non-stream data set as input.
Data flow is a scalable pipeline that can accept input from different sources, transform and enrich the data and then send the processed data to the destination.

Fun scenario: Use the data flow to process the YouTube metadata that is related to “Chelsea FC”. Filter only the official Chelsea videos from their own Youtube channel ‘Chelsea Football Club”. Show the videos in the User portal.
So the output data flow will look like this.

Let’s start with the rule configuration.
What are all the configuration points in a data flow rule?
Step 1: Create a new data flow rule
Records -> Data Model -> Data Flow -> Create New

As soon as you create, you will get the default source and destination shape.
Note: You see the data flow configuration is hybrid version of flow rule and strategy rule.

As of Pega 8.4, we have a total of 10 components or shapes, including the source and destination.
What are the different components in the data flow rule?
- Source
- Processing components – Compose, Convert, Data transform, Event strategy, Filter, Text analyser, Merge, Strategy

3. Destination
1. Source shapes
Source can be configured from one of the 4 options.
a) Abstract – Use this option when your data flow input is either from an activity execution or from another data flow where the destination is configured to the current data flow.
Note: Destination component of a data flow can always refer to another data flow.

b) Data flow – here the current data flow invokes the source data flow to get the input data
c) Data set – Use this option, when your data flows from a data set rule.
d) Report definition – Use this option when your input data is from database or from elastic search.
Note: Now report definitions supports querying from elastic search.
In our scenario, I am going to use the data set we created before.

2. Processing shapes
a) Compose – Combines data from two sources.
Scenario: Let’s say a Banking organization needs to create a customer data set. There are two source systems involved. CRM system that contains the customer details for the customer ID. LPS system that contains the loan details for the same customer ID. You can use Compose shape to combine or enrich the customer data set with both customer details and loan details for a customer ID.
The output from the compose shape will be one record – something like inner join in SQL.

So you can compose (enrich) the data based on conditions.
b) Convert – you can change the class of the incoming data.
This is something similar like mapping integration properties to data properties. You can use field mapping to do multiple mapping.
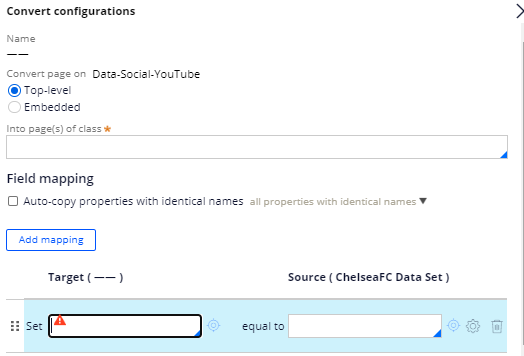
c) Data transform – Nothing to explain J You can call a data transform rule.
d) Event strategy – Again this shape can be used to call the event strategy rule.
e) Filter – Use this shape to filter only the necessary data that we need to process.

As per our requirement, we need to filter only the YouTube videos that gets officially published by the Chelsea official YouTube channel.
So I added a filter condition – pyAuthor = “Chelsea Football Club”
f) Text analyser – You can make use of the text analyser rule to derive the business information from the incoming data.

g) Merge – This is somewhat similar to Compose shape. The only exception is it merges the records from multiple sources and output all the content. You can imagine it like Union in SQL.
For example, for the same Compose scenario when the LPS system contains five loan numbers for the customer ID, the result will be 5 records.

h) Strategy – This shape calls the strategy rule.
Destination shape –
Here you configure the destination where your data set results can go.

There are 5 types of destination output
3. Destinations
Abstract – Choose this option when you want to use this data set as a source to another data flow rule.
Activity – You can use an activity rule as output to process the data.
Case – You can also invoke a new case and do some data propagation on case creation.

Data flow – using this option, you can invoke another data flow rule.
Data set – you can specify a data set as output.
Think of a scenario, where you need to store the data into a database table. Here you can create a new destination data set that is of type – database table and refer to the data set in the destination component.
You can also branch the destination component using Add branch button.

When you want to process the same data source in different ways, you can always use the branching technique in the data flow rule. By this way, you can avoid creating multiple data flow rules for the same data set.
For tutorial purposes, we will see how to create a new case with every input data.
As a pre-requisite, I created a new case type – YouTubeVideos and created a Page property – YouTubeVideoDetails of class Data-Social-YouTube
I mapped the Author name, URL and description as data propagation to the new case.

Okay, now our Data flow is ready.
Let’s do some unit testing.
How to invoke a data flow rule?
1. Manually run the data flow rule

You see, you cannot execute the Data flow, because the current node is not classified as RealTime.
Note: Pega recommends to use a dedicated node type for RealTime processing.
Let’s try adding the RealTime and batch node type to the personal edition server.
You need to update setenv.bat file.
Please follow the link for more details.

Don’t forget to restart the server 😉
Once the RealTime node is up, you should see it under
Configure -> Decisioning -> Infrastructure -> Services -> Data flow, under RealTime service.

Now try running the activity manually yourself.
2. Using the activity method – DataFlow-Execute
You can perform different operations on the data flow – Start, Stop, Get progress
You can also specify the Run ID, that will uniquely identify your run.

You can start the data flow rule on different service instance. I am going to add it to RealTime node instance.
Run the activity manually.
Switch to Configure -> Decisioning -> Decisions -> Data Flows -> Real-time Processing
You will see a new Data flow run for Run-1 (the name we provided from the activity)

Click on the ID – Run-1 to view the real-time data flow
You see currently 150 records are processed and 18 videos are filtered as Chelsea official videos.

You will also see cases are getting created continuously for all the YouTube videos.

Open any case, to check the clipboard, to verify the mapping from the data flow rule.

All good.
Important note: Real-time processing will keep on running until it is stopped manually
Okay, we saw something new here.
Data flow landing page and Data flow run. Let’s discuss it.
What are the features of the data flow landing page?
Switch to Configure -> Decisioning -> Decisions -> Data Flows
You see there are 4 tabs.

- Batch processing
- Real-time processing
- Single case processing
- External processing
The above example we saw falls under Real-time processing data flows.
Pega classifies the data-flows automatically based on the source data set in the data flow rule.
For example
– If the input data source is of database table, then we can do batch processing.
– If the input data set is of type streams, then it falls under Real-time processing.
That is the reason when you executed the data flow manually from the activity you see a new RealTime Data flow run 🙂
How Pega manage the data flow run?
Step 1: From the Real-time processing landing page, open any existing run.
Step 2: In the clipboard, you will see a new case instance of class
Pega-DM-DDF-Work.

So for every data flow run, Pega maintains the case.
How to start a new Real-time data flow run?
Step 1: Switch to Configure -> Decisioning -> Decisions -> Data Flows -> Real-time Processing
Step 2: Click on Add New button
Associate a data flow with this run.

Applies to – specify the class on which you created the data flow rule.
Data flow – specify the data flow rule
Access group – Specify the access group so that the data flow can run on the access group context.
Service instance name –
You can specify on which node this data flow to run.

In the ideal scenario, you need to classify a node as RealTime and run the data flow on the RealTime node, but you always have the option to make use of the existing BackgroundProcessing node as well.
I am going to usethe Service instance name as BackgroundProcessing
Number of threads –
We will talk something about scaling first.
Based on the load, we can either scale up or scale down resources. Resources can be of servers, threads, CPU size etc.
Horizontal scaling
Say in a production Pega application there were 100 end users using the application to perform customer servicing. Currently, there are only 2 WebUsers servers. Due to this COVID-19 situation, the workforce is doubled and hence new users were hired to use the application, say the count is 200 now. The increase in workforce results in performance downgrade during the peak hours. Architects now make a decision to scale up the servers or nodes for WebUser.
So they planned to add 2 more production machines.
This is called horizontal scaling.
Vertical scaling
In the same scenario, instead of adding two new machines, the architect can decide to add extra CPU to the existing machines and increase the RAM size to counter the performance impact.
This is referred as vertical scaling.
You know where multi-threading falls. Of course it is vertical scaling!
Pega provides a edit setting configuration to add a number of threads per node. For the real-time nodes, switch to Configure -> Decisioning -> Infrastructure -> Services -> Data flow
Click edit settings. You see by default thread count is 5.

Now getting back to the data flow run configuration.
As per Pega help on data flow threading, the maximum thread size depends on your server CPU cores.


We will use thread as 2.
We will have a discussion about partitions in the later blog article.
You can also associate your run with the ruleset and run ID. So that any changes you to on the data flow run will be easily affected.

Additional Processing
You can also specify some additional pre-processing and post-processing activities to run before and after data flow run.
Important note: pre and post processing activities run only once

Resilience
This block is responsible to do some error handling for the data flow run.
It is separated into two parts
- Record failure
- Node failure
Record failure –

You can specify the error limit. Once the limit is crossed then the data flow run goes to failed state.
Note: There is a DSS setting to maintain the limit globally.

Node failure –
Restart the partitions on other nodes – The name explains.
The options vary based on the type of data flow run – resumable or non-resumable
Please visit an archived post for more details –
https://community.pega.com/knowledgebase/articles/decision-management-overview/data-flow-run-updates
based on the data set, data flow run can be categorized as resumable and non-resumable.
We are done with the data flow run configurations. Click the Run button now.
Run is getting initialized

In the data flow run, you have 3 main tabs, that give you the statistics of the data flow run
Component statistics –
This will give you step by step statistics on each component or shape in the data flow rule.
You see below the filtered results.

Distribution details –
You can see the distribution across nodes and partitions.

Run details –
Here you can see the statistics about the run.
View lifecycle events link, to view the lifecycle.

Now we are good with the Real-time data flow run.
2. Batch processing
This is different from the Real-time processing. As I mentioned before, the type of data set determines the type of processing.
- Stream data set – Real-time processing
- Non-stream data set – batch processing.
For batch processing data flow run, the data flow stops once the main input is read entirely or when it is stopped.
For real-time processing data flow run, the data flow stops only when it is explicitly stopped, otherwise it keeps on running forever.

Other than that, the configurations are all same for the data flow run.
3. Single case processing
When the data flow source and destination is configured as Abstract, then they can be considered as single case processing.
These data flows are invoked by the DataFlow-Execute method.

Note: You cannot add a new data flow run manually from the landing page.
4. External processing
This is specific to data flows that process Hadoop record. This landing page is exclusive for external data flow runs.

As a summary,
– Data flow rule allows you to combine the data from various sources and write the results to a destination.
– Stream data sets can be categorized under Real-time data flow and non-stream data sets can be categorized under batch data flow.
– Data flow rule can source from data set, data flow, abstract and report definition.
– There are different processing components to enrich or transform the data.
– Data flow rule can send the data to different destinations like run activity, create case, invoke data flow or data set rule.
– It is advisable to use RealTime or Batch node types when you are involved with millions of data, but you can associate data flows with the BackgroundProcessing node type as well.
– Data flow run can be initiated from the landing page Configure -> Decisioning -> Decisions -> Data Flows -> Real-time Processing and creates a new case instance of class Pega-DM-DDF-Work
Hope you learned something new in this data flow post.



