Integration Mapping – Parse delimited in Pega

In this blog article, we will see more detail about parse rules and different parsing methods
Parse delimited rule operates mostly in conjunction with service file rules that are used in file processing.
What is file processing?
We know that almost all applications work with data. Data can be captured in multiple ways. The most common way of capturing data in pega is from end user portal.
We store the data as properties in Pega
Capturing data from the end user portal is not the only way of receiving data. Data can be received via web services (REST, SOAP etc), messaging services, emails and files.
Let’s concentrate on the data we receive from file services.
Enjoying this content?
Access the author’s full video courses here at MyKnowAcademy.
Explore Courses →
We know that Pega can communicate with other systems ( Java, DotNet..) via services. If we need a load of data from other systems, we can prefer to receive the data in a file. So an agreement can be made with an external system in such a way that the external system feeds us a file ( daily or weekly or in any time interval).
We have to use the data from the file and map it to Pega properties. So that we can use the data and process within Pega.
Pega provides certain parse rules to map the data we receive from the external system to the Pega system.
The available parse rules are
- Parse Delimited
- Parse Normalize
- Parse structured
- Parse XML
I am making a full stop here on file processing. You can find a detailed explanation on file processing in separate articles
In this article, We will concentrate on Parse delimited rules which are being extensively used in file processing
What is Parse delimited rule?
– The parse delimited rule is used to parse the data from files and map to pega properties.
– Any character can be used as a delimiter and can be used to distinguish data.
Note: Normally when an external system provides data, they always use some delimiter ( comma, | or quote to distinguish data)
If a comma is used as a delimiter then the raw data Premkumar,G,Male can be mapped to FirstName, LastName, Gender properties.
Where can you refer a Parse delimited rule?
1. Used mostly in conjunction with Service file rules.
2. Can be used in activity using Apply-Parse-Delimited method.
What are the configuration points in the Parse delimited rule?
Let’s start by creating a new parse delimited rule
Step1: Records -> Integration-Mapping -> Parse Delimited -> Create

Record Type can be used to group similar delimited rules used for specific purposes. I just named it as sample and I have more than one parse delimited rule with record-type sample.
Step 2: Create and Open

Parse rules are the single main tab that contains the entire configuration
In the Parse rules tab, we may need to configure 3 blocks
- Field description
- Processing method
- Parsing details
Field description
Field format – Indicates the format of the input data

It can be either comma-separated values or a custom definition
a) Comma-separated values – Name explains. Comma acts as a delimiter.
Always used when the supplied input file is in.CSV format. You can always export an Excel file to CSV file.
Demo, we will see in the later part of the post.
b) Custom definition – You can define some custom delimiter options

Here, again I have used comma as a delimiter.
Escape character – Why do we need this?!
Let’s say an example in which the customer details are provided as input
The three customer fields are Name, Gender and Address
Prem,Male,TamilNadu,India
Here I need to map below
Name = Prem
Gender = Male
Address = TamilNadu,India
But will it parse like that it we use a comma as a delimiter?! Yes and No
Yes – When you use a proper escape character. I have specified ‘/’ as an escape character and then my input data should be Prem,Male,TamilNadu/,India
Now you know what is the role of an escape character.
The escape character should always come before the delimiter which needs to be ignored.
Processing method
This block allows us to select any one of the parsing method

Method – You have 4 different parsing options

a) Build tag list
b) Use tag list
c) Use parse details
d) Build value list
c) Use parse details
(Don’t think we skipped tag lists, wait for it!)
On selecting this option, you can use the parse details block to specify the parsing details
Drain remaining data

Say, for example, an external system provides a hell lot of data in the input file. If we are interested in only the first 3 fields, then we can parse only the first 3 fields and drain the remaining data.
Most of the time, we use ‘drain remaining data’ option selected!
Parsing details
This block is only used by two parsing methods – Use parse details and build value list method

Required – You know why it is used. Parsing will stop if the required field is not available in the input file data
Description – I won’t explain
Map to – You get different options.

It contains two blocks.
1. Select a Map to value – Here you can either use a clipboard property to map directly or we can also refer to other parse rules like XML parse rule, delimited parse rule and structured parse rule.
2. Select a Rule-Utility-Function – Here you can use the functions that belong to MapTo library.
For now, let’s use the clipboard as map to
Map to Key – Based on the Map to type we can specify the key
Since we used clipboard, we need to use a property.

Time to test.
How to test a parse delimited rule?
Step 1: Create a new parse delimited as shown in this post
Step 2: Do the following configuration
Field format – Comma-separated values
Method – Use parse details
Parsing details – Map to two clipboard properties pyLabel and pyNote

Step 4: Run the Parse delimited rule and provide the input as below. Select Text to be parsed.

Step 5: Open the tracer and click on execute.
Note: You can select the parse rule from tracer settings.

Click execute and check the tracer rule.
You can see, parse rule executed successfully by parsing the input using delimiter.
pyNote = Parsing; pyLabel = FirstTest

Good.
Repeat steps 2-5 using different field formats and test it.
Let’s check the escape character configuration.
Step 1: Do the following configuration
Delimiter as % and escape character as &

Step 2: provide the input as shown below.
For example, Some people use alias in their name. In such case, when @ character is used as a delimiter then it will recognize alias @ as delimiter character. We need to specify an escape character to overcome it
Myknowpega@Ravi&@Raj

So, & character should escape the delimiter @ preceding Raj
Step 3: Trace and find it out on the page.

Now let’s check the other parsing methods
d) Build value list

Do you know when we need to use this option?
Just select this option empty the parsing details block and try to save it.

You see two restrictions in the error message
– Only one line should be configured in the parsing details block.
– It should map to a clipboard property of type value list!
Scenario: say, the external system is sending out the list of phone numbers as a comma separated value and you need to store the phone numbers in a value list property PhoneNumber
Step 1: Specify the below configuration in the parse rule.

TelephoneNumber is an OOTB value list property.
Step 2: Run the parse rule and provide the input as shown below
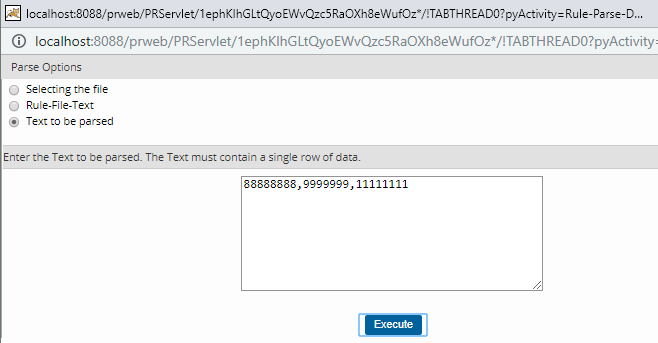
Step 3: Check out the tracer output. It must be seen the phone numbers are built in a value list property ‘TelephoneNumber’

The last two methods are twins 😉
We usually use it together.
a & b)Build tag list and use tag list

What do they do?
Build tag list – builds a value list (same as build value list) but they use standard property – pyTagList defined inbuilt and gets mapped to a Page ‘Work’. You cannot change these default settings!
Why it is designed like this, and where will it be used?
It can be used by another parse rule with a parsing method use tag list 🙂
So use tag list parse method always expects the pyTagList value property in the page ‘Work’ .
So, Build tag list and use tag list are tag team partners.
Still confused?!
I will give you an example.
Imagine, an external system sends out the name and age of a customer in a CSV file. The header part (first row of the CSV file) contains the pega property names that hold the values in the below rows.
Something like this

Here, the first row corresponds to pega properties Name, Age. The other rows correspond to the values.
Note: When you use build tag list and use tag list option, keep the Parsing details block empty, because it is of no use, because you use the OOTB property .pyTagList.
Let’s see it in action.
Step 1: Use the below configuration in the parse delimited rule as shown below
First, we build the tag list.

Step 2: For now I don’t want to use any file. We will use it in my next post.
Use the first row input data. Name and Age
Note: Name and age should be created already as a pega property. If no pega property is available, then page validation may fail

Step 3: Execute. No need to trace. Click on the clipboard to check the page Work in thread standard.
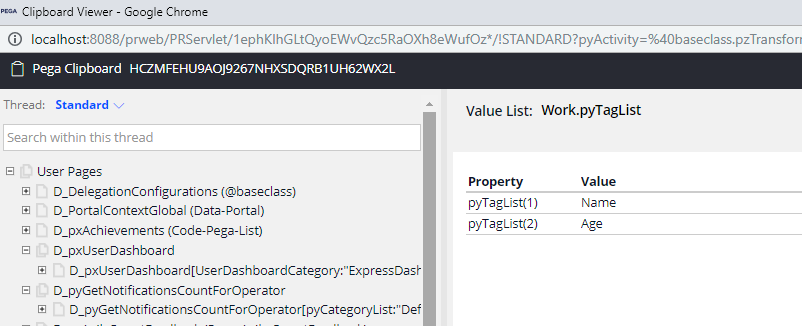
Now we have successfully parsed the header and mapped to pyTagList property.
Step 4: for testing, just update the same parse rule with use tag list method.

Step 5: provide the input value corresponding to the header we parsed in last run.

Step 6: Open the tracer and execute it
Note: Only build tag list creates a new page Work and save the header in pyTagList. Use tag list method uses the .pyTagList values (properties parsed) updates the value in the primary page.

Now you know the use case of build tag list and use tag list.
Build tag list parses the header line and use tag list saves the data corresponding to the parse header line.
Pega already has two MapTo functions doing similar jobs.
OOTB MapTo functions
1. parseCsvHeader
Parse the header line and save it to .pyTagList property. You can check the underlying Java code.

2. ParseCsvDetail
Finds the workpage and uses the .pyTagList values to parse the data

Good!!
We know that parse delimited rule can be used in service file rules and activity rules.
How to use parse delimited in the activity rule?
Use ‘Apply-Parse-Delimited’ method to reference a parse delimited rule.
Note: In activity rule you can always parse a string using a delimiter
In this example, we are going to recreate the phone number example using build value list
Step 1: Create a new test activity ‘ParseSample’
Step 2: Add a property-set step and add a phone number string to pyLabel

Step 3: Use the configuration in the parse delimited as shown below

Step 4: Now, add a new step in the activity rule with method Apply-Parse-Delimited and add the Parse delimited rule.

Method parameters: Namespace and RecordType are used to identify the parse delimited rule and the SourceProperty should refer the property or parameter that holds the input data string
Step 5: Save the rule. Trace open and run the rule

Done.
You can continue with the service file configurations in the below blog



