Data Pages Usage & Configurations in Pega

In this blog article, we will try to understand the in-and-out of Data pages configuration and usages.
This article was created using Pega '24 version.
Before getting into data pages, let’s understand about memory, caching and clipboard pages.
Let me start with a very simple example. Imagine you are a YouTube Chef 😊
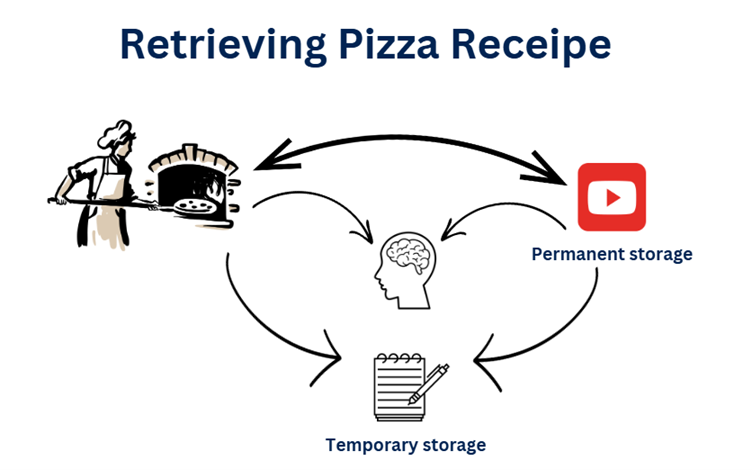
You want to bake a nice Pizza, you go to YouTube find the right video and make it perfect. Let’s say after couple of days, you want to bake another Pizza, you go to YouTube again, watch the same video, done. Another day another YouTube video view.
Now what if you store the recipe in your brain memory or on sticky notes so that you can avoid hitting YouTube again and again.
Compare this with any Java application processing, how does the application uses the data for processing?
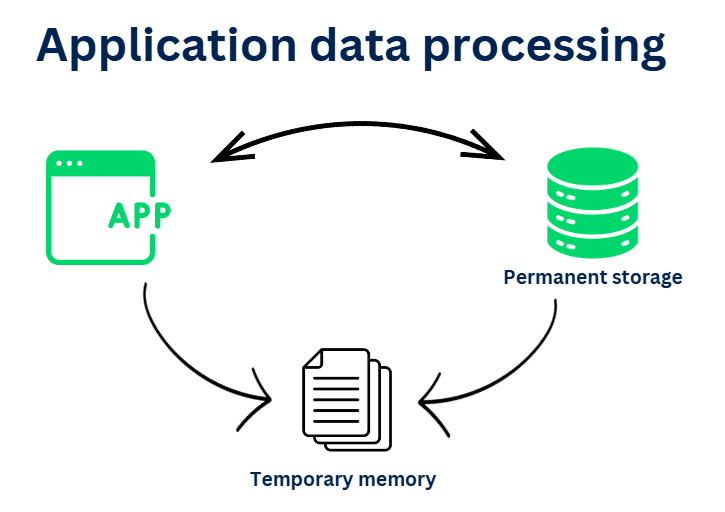
Permanent storage – Applications can use some persistent storage like database to permanently store the application data.
Enjoying this content?
Access the author’s full video courses here at MyKnowAcademy.
Explore Courses →
For example – Take an example of an Organization HR application. All the employee details can be permanently stored in the database.
Temporary storage – Applications may need to use those data or objects for processing. To access these data, we don’t need to hit the database every time. Instead, we can load and store the data in the memory to avoid database trips. The temporary storage can be of the heap memory where the Java objects can be stored.
Same like Java applications, Pega applications also use temporary memory and permanent storage for application processing. In the end, Pega is built over Java right.
Let’s concentrate only on the temporary memory store.
Let’s take another Java Vs Pega comparison
In Java application development, we can have class, say Employee as a class.
The employee class can have Java objects like emp-1, emp-2, etc…
These objects can be stored in the heap memory and can be cached there and accessed at any point of application processing.
In Pega application. We can have a data class and those classes can have instances (Java objects).
The Java object can be compared to a clipboard page and the collection of Java objects can be compared to the Clipboard.
The below picture gives a clear picture on Pega concept and Java equivalent related to memory.

Important note: Going forward in this article, I will be interchangeably refer to Pega clipboard pages as Java Objects to get the core understanding clear 😊
Now we know Clipboard is a virtual collection of objects or pages that are stored in memory.
Login to your dev studio and open the clipboard from the bottom panel.
Pega classified the clipboard pages into four main categories in the clipboard.
Let’s take one step back and come back to these types of clipboard pages later in this article.
Let’s understand the memory structure in a Pega application
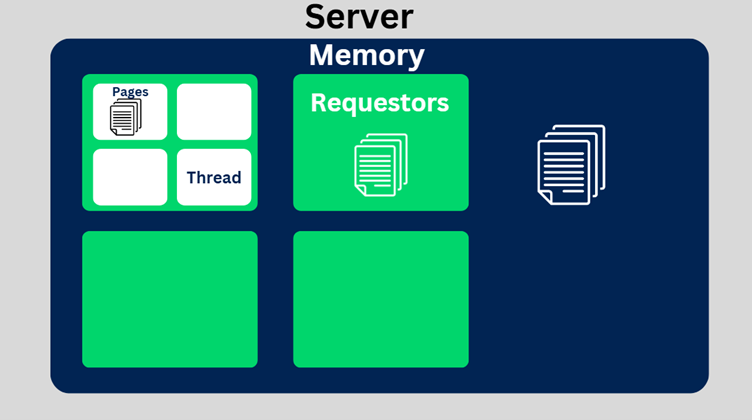
From the above picture, we see 4 subset layers.
Server – Refers to the pega servers or nodes where the Pega application is deployed and is running. It can be Apache Tomcat server. If you are running personal edition, you can consider your laptop as the physical server.
Memory – Every server will be configured with some default space reserved for memory. The memory area can be sub-divided into stack memory, heap memory, permgen and others, but for now let’s not get more deep into it. We will call it simple ‘memory’
Inside the heap memory is where all the Java objects, in Pega terms the pages with data (UserPages, System pages, Data pages) are stored.
If you are familiar with basic programming, you must have heard about this variable declarations – Global variables, local variables right? That determines the scope of the variables.
Similarly, the Java objects or the Pega pages can be globally used or it can be locally for requestor sessions or it can also be local to specific thread which we will see shortly!
A good example is Node level data pages.
Requestor level pages – Inside the memory area, for every requestor session (it can be browser requestor, batch requestor or any other requestor type) there can be multiple java objects / pega pages.
There will be some pages whose scope is on requestor level.
For example – Almost all of the system pages are requestor scoped. On the system pages, you will find a page called OperatorID pages which holds the requestor details and is always available throughout the requestor session.
Threads
Certain Java objects can also be scoped under threads.
For example, when you open any case, it takes up a thread context and certain Java objects/pages comes under thread scope.
A good example is ‘pyWorkPage’ which is the primary OOTB page that holds the case data/ object in the memory.
So now you may get a question, what is the role of clipboard here?!
– It provides a Clipboard Viewer, which is a graphical interface that allows developers to view and interact with the data stored in these Java objects
– The Clipboard Viewer doesn’t create new data; it just visualizes the existing Java objects and their properties on the clipboard in a hierarchical, structured format.
– Developers can inspect the values, structures, and relationships of pages and properties that Pega is managing in memory, helping them debug, analyze, and understand the data flow in their application.
Okay, now let’s launch the clipboard viewer again and check the pages.
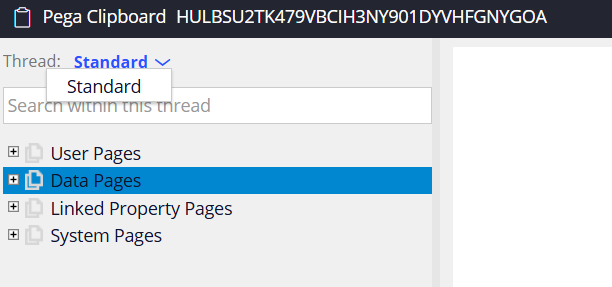
In the top header, you see the requestor ID for the clipboard.
You also see we can switch between threads if needed. Ofcourse in the user portal, you may be opening different cases and so different threads with different pages.
1. User Pages – Almost all of the User pages are thread-specific and can be accessible only within the thread scope.
In the below picture, I created a new case and so you see the thread name as M-2001.
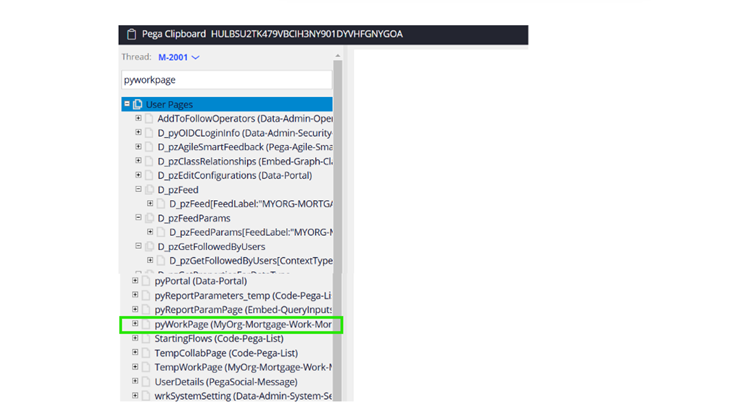
pyWorkpage is more a reserved page name or Java Object, which Pega creates on opening or creating a case and holds all the case details. This object scope is only restricted to Thread.
Similarly, you find a lot of other user pages in the clipboard, which is more thread specific.
2. Data pages – We are going to extensively see about the data pages in this article very soon, let’s wait for it 😊
One Important point to note is – Read-Only data pages are only available in the Data pages block. The editable data pages can also be found on the User pages block.
3. Linked property pages – these are special types of properties that allow you to establish a connection between different data objects by referencing data from related classes.
More about this in a dedicated blog article.
4. System Pages –
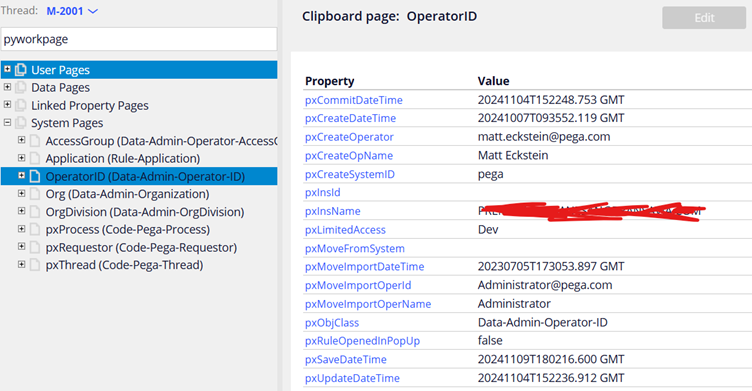
All these pages are automatically created by system to maintain the state of the operator or the requestor session. Also to load some operator specific data like – Application, access group, organization, division data.
Note: We can never create system pages and they are mostly read-only!
Finally, the introduction story is over, Let’s talk about data pages 😊
Why data pages?
Let’s start with a business scenario.
Scenario: Imagine some insurance call centre’s CS application is using Pega. All the customers information are stored in different applications and policy details are stored in Pega DB.
So when a customer calls in call centre for an enquiry, we may need to use connectors to connect with other applications to get customer data and use a database connection to get the policy details.
When the call centre agent processes the enquiry ( like navigating screens or flow steps), we need to access the customer and policy data again and again from other applications.
If we try to hit the database or make API calls every time, this can be very time consuming and can bring performance degradation.
Solution: So instead of accessing data from DB or other applications, we can pre-load the data in memory and improve the performance.
Here we can use data pages D_Customer, D_PolcyDetails to pre-load the data in clipboard and use it whenever necessary.
Note: From the clipboard you can easily identify the clipboard pages, as they always start with D_
When we refer the data page in any rule, the data page gets loaded in the clipboard. At the backend a Java object gets created.
On subsequent access, the data pages never gets loaded, because the object or page is already loaded in memory and can be reused right!!
Loading of data pages can be controlled by the refresh strategy configuration which we configure in the data page rule.
Now you may ask, why do we need data page first?!! Why can’t we load the data in some user pages and use it at every place?!!
There are two main reasons, why we need to use data pages.
1. Declarative processing – If you have started your Pega career in older Pega versions, you must have known about declare pages, which was later renamed to data pages 😊
Still in clipboard, you see some of the data pages start with older naming conventions as Declare_
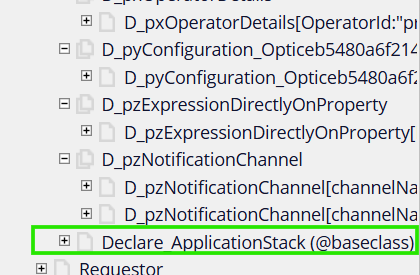
Data pages are actually declare pages in the first place 😊, and so they can be loaded declaratively when referred. Loading configuration can be done at the data page rule
2. Scoping Data pages – User pages are always thread scoped, where as data pages can be scoped at different level like thread level, requestor level and node level and can be reused across threads and requestors.
What is a data page?
– Data page belongs to data model category.
– Data page can be of single page or a page list with multiple pages.
– Data pages starts with D_ or Declare(Legacy support).
– You can pre-load the data page as well as clear the data page.
– Data pages can be editable/ Read only.
– Data pages can accept parameters.
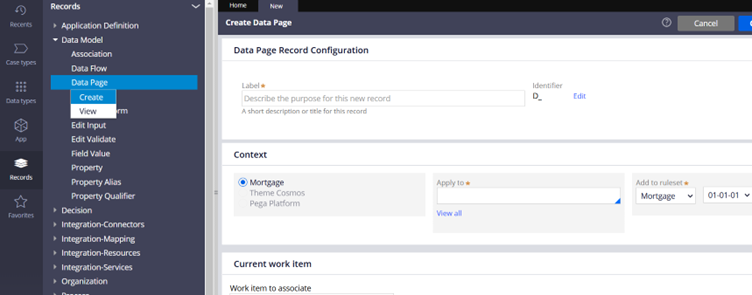
How to configure a Data page?
You can create a data page for any work class or data class.
Records -> Data model -> Data pages -> Create new
Pega also automatically creates data pages at multiple places
1. Whenever you define a data type, Pega creates three types of data pages. We already saw about this in a separate article.
2. Whenever you create Integration and Data mapping using wizard, you get an option to define data layer and data pages for it.
I will use one of the data page which is already created as part of data type creation
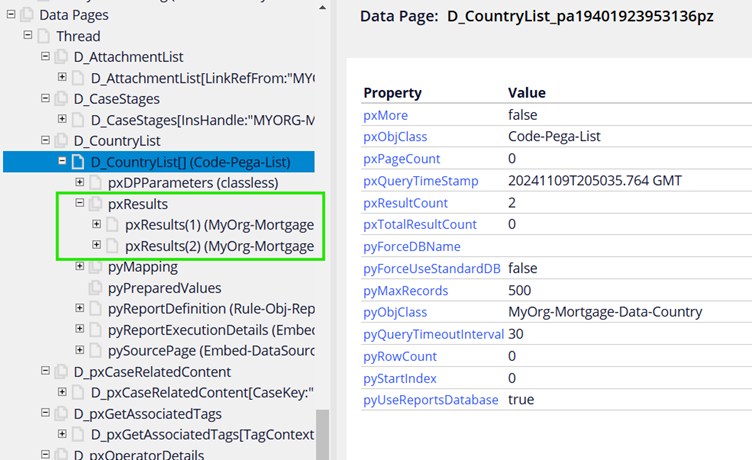
D_CountryList
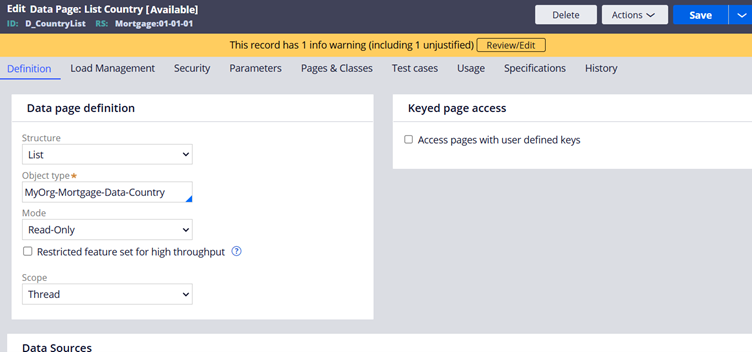
There are 3 main tabs.
1. Definition tab
I would say data pages can be classified into different types, based on different categories.
First let’s classify the data pages based on it scope
a) Types of data pages based on scope
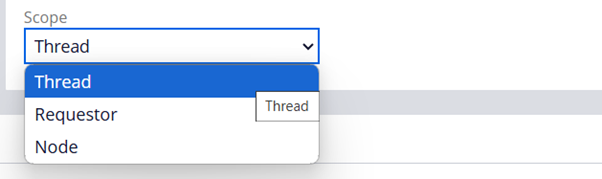
In the introduction part, we already talked a lot about how pega application effectively uses the memory structure by defining the Java objects / pages under different scope.
This is also a clear advantage between using data pages and user pages.
You can control the scope of the data pages by defining the configuration
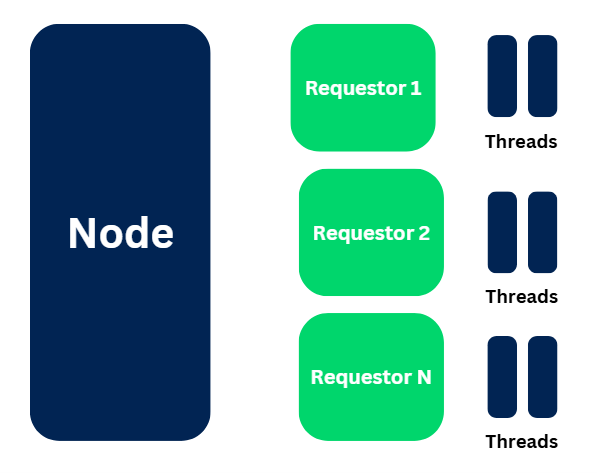
1. Node specific – When you configure any data page as node specific, then data page can be loaded once in the server and can be reused across requestor or sessions.
When a data page is configured Node specific, then you may get additional configurations.
– Data page is always read-only.
– A mandatory access group to be specified. Normally the data pages when specified as requestor or thread scope, then it loads on the current user access group context. But when it is on server load, we need to specify the access group to specify the context
Example Scenario – An example of node specific data page can be of D_CurrencyList. When you find some data, that doesn’t change very often and will be same across requestors, then you can specify it as node specific data and load it once to reuse it.
In the clipboard, you can also find some node specific data pages.

You see an OOTB example D_pzGetAuthServicesList that loads all the authentication service rules available in the system
2. Requestor specific – When you configure any data page as requestor specific, then the data page can be loaded once for the requestor session and can be reused across threads.
Example Scenario – Let’s say for a Sales application, we need to add discounts D_CustomerPerCustomerType based on customer type. This is a data configuration and can be loaded requestor specific and can be reused across threads or cases.
Let’s look at the OOTB requestor scope data pages
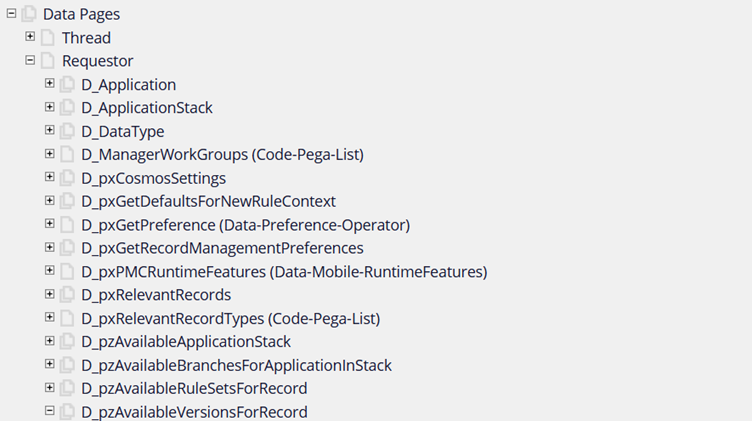
You can easily identify a lot of OOTB data pages that are requestor specific – like D_Application.
3. Thread specific – When you configure any data page as thread specific, then data page can be loaded once for the specific thread and can be reused across that specific thread or case.
Example Scenario – Very easy example – D_Customer, D_LoanDetails, that can load the customer or load details on thread specific or case specific.
Let’s also look at some of the OOTB thread specific data pages
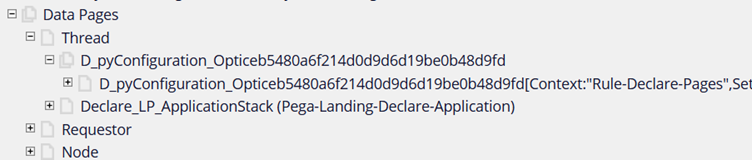
b) Types of data pages based on structure
Hope many of you already know about different types of embedded properties like Page and Pagelist.
Page – holds the single object
Pagelist – holds multiple objects as separate pages.
A similar type of configuration is available in the data page as well, so you can control one or more data objects that can be embedded inside a data page.

Page – The data page can be treated as single page structure. Ex: D_Country refers to single page or single Java Object with single country details.
PageList – This data page can be treated as a pagelist containing multiple pages (Code-Pega-List) results. Ex: The one which we see above D_CountryList refers to many country details embedded into a pagelist as separate pages.
c) Types of data pages based on edit mode
Data pages are not only read-only just to load the data, but also it can be of Editable mode (where the data page can be updated) or it can be Savable mode.
Note: Savable data pages is introduced in Pega 7.4 version.
Detailed explanation on Savable data pages in a separate blog article
1. Read only – As the name implies this datapage is pre-loaded and cannot be updated. All node level data pages are read only.
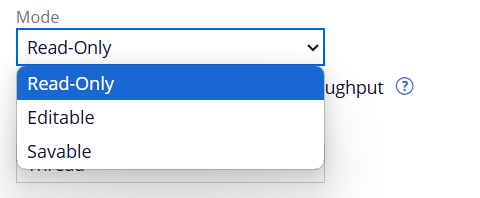
You can see that if you select editable, then the scope will be limited to thread and requestor.
You can find the read-only data pages under ‘Data page’ category, whereas editable data pages are in ‘User pages’ category.
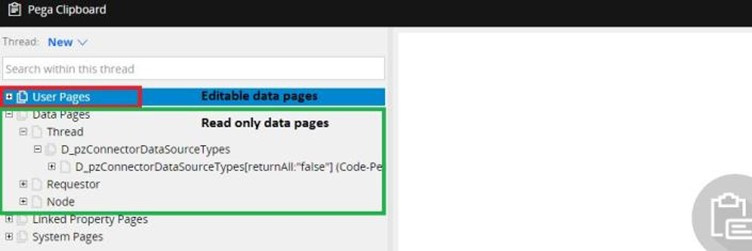
2. Editable – Data pages can be editable. You can find it in ‘User pages’.
3. Savable data pages – A dedicated lecture on this topic in a separate blog article 😊
b) Object type – Specify the class of the data page. It can be either work class or data class.
In our data page, ofcourse it will be of data type class – MyOrg-Mortgage-Data-Country
What is keyed page access?
This is applicable only for Pagelist structure and mode – read-only.
Remember, we have a Datapage list D_CountryList which contains details for all the Countries list.
We can use the same data page to get the details of a particular country instead of the entire list.
Example: Imagine you need to check a particular chapter in a book. If you know the page number, then you can directly switch to that chapter right. This is called ‘keyed page access’.
Like the same, you have D_CountryList(book) containing different countries (chapters). If you need to access a particular country, then you need to know the country code (page number) to access.
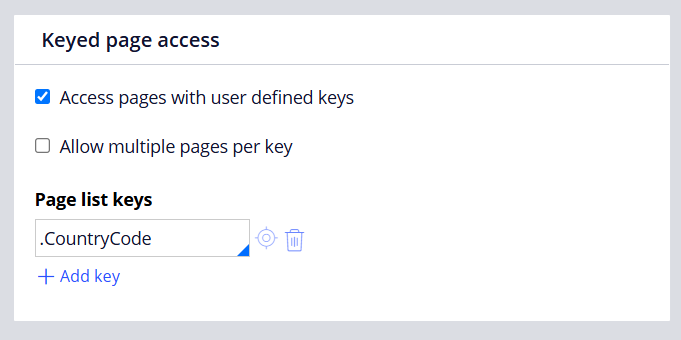
Keyed page access
Access pages with user defined keys – Checking this will enable you to access particular pages using keys.
Allow multiple pages per key – Checking this will allow you to return more than one page using keys. Just think single policy ID can return multiple policies. (I am saying this, just for example).
Pagelist Keys – You can specify multiple keys to access.
Advantage:
– You can make a single data page to be used as both pages or pagelist structure.
D_CountryList can return all policies, also keyed page access can return single Country details.
– Avoid multiple rules management.
Restricted feature set for high throughput – This option is applicable only when the data page is configured as read-only.
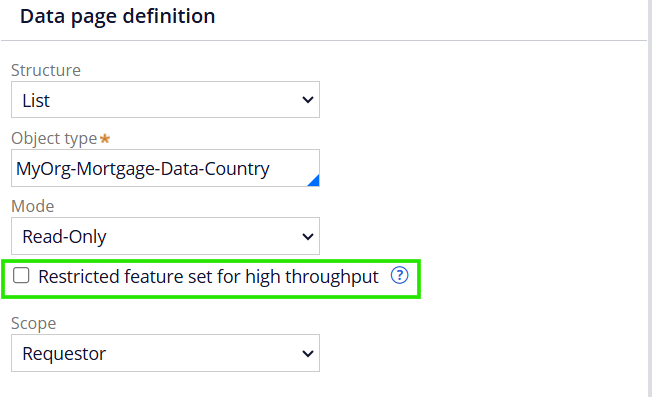
Pega gives a warning message in the help icon saying ‘On enabling the data page do not support clipboard API’
It means the Declarative processing, property-ref references are not applicable and will not be fired. Careful consideration is needed when you use this option.
Use it only for static simple content without any declarative processing like declare expression or other rules.
Data Sources
We know data pages are of declarative type. So of course we have the control to configure the source of the data pages in the data page rule configuration.
Data sources also vary based on the page structure – page or page list
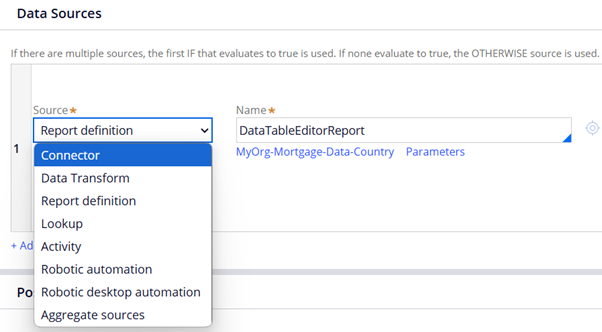
1. Connector – You can specify the connector type with connector activity. You can also specify the request and response data transform, end point URL.
You can see we can use different connector protocols
These data pages act as a primary page for the connector rules and can contain the response within the data page.
2. Data Transform – You can specify a data transform rule to map the data to the data page rule.
3. Lookup – You can specify a class to get a particular class instance. You can also specify a response data transform. Appears only when data page structure – Page
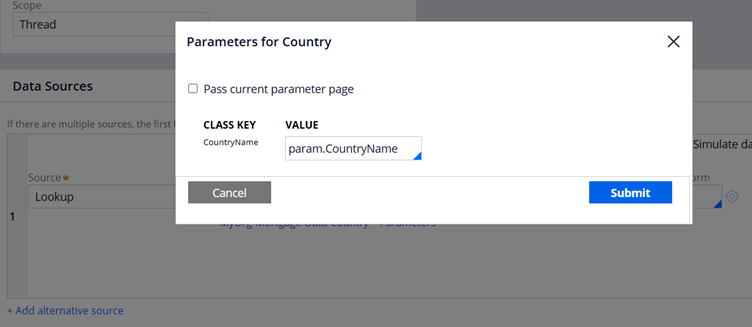
You can get the details of a Service Request work item in a data page, by passing the work item ID using look up option.
4. Activity – You can specify an activity rule to load the data page with data.
5. Report Definition – You can specify a report definition rule to get the results and load the data page. Appears only when page structure – Pagelist.
6. Robotic automation and robotic desktop automation – Used for robotic processing. Not used very often.
7. Aggregate sources – You can use one or more sources and append the results to the data page.
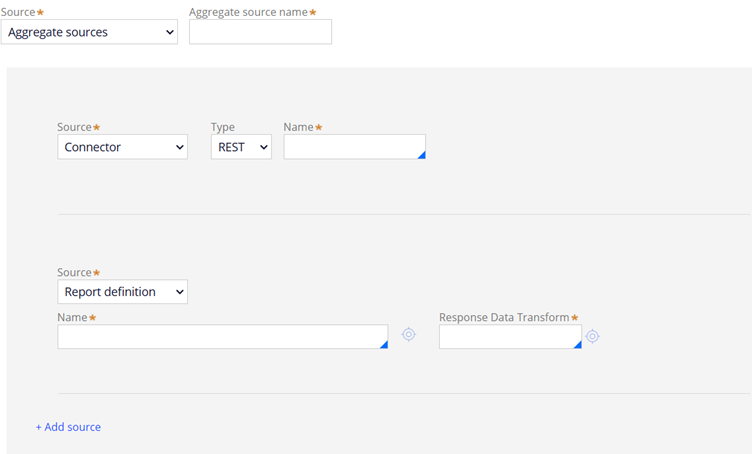
Add alternative source – You can configure multiple source and control the source selection based on If (when) otherwise conditions
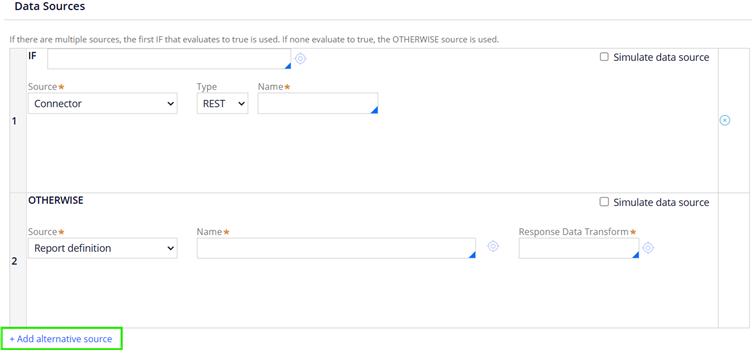
Simulate data source
During development, when data source is not ready, you can simulate the data source for testing.
Check the simulate data source on the right corner.
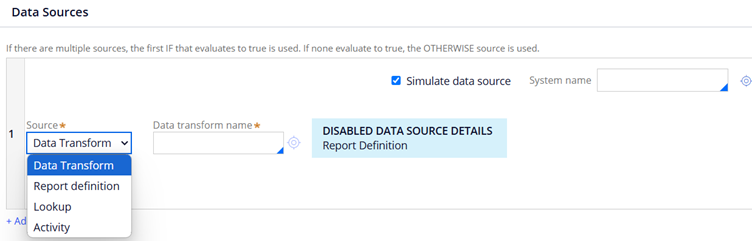
You have four options to simulate the source.
Data transform, Report Definition, Lookup, Activity can be used to simulate the source.
Post Load Processing
You can specify a post-load processing activity to process the data page after loading.

This is mainly used in error processing. Remember if the data source returns invalid data, then we can have logic here to process the errors.
Note: When you configure the Savable data page, then you get a new block called Savable data options.
2. Load Management Tab
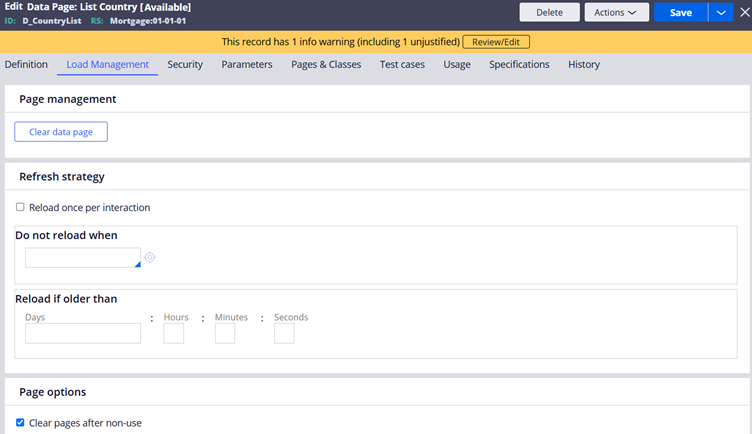
Page Management – Clear Data page
You can click on clear data page to remove the data page from the clipboard.
Refresh Strategy for node level data page
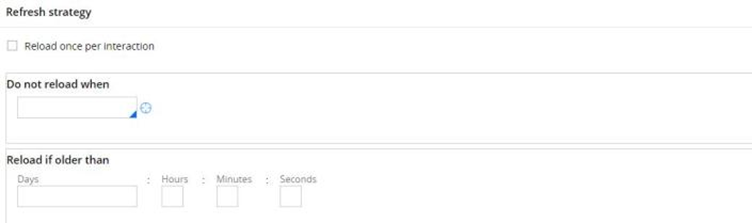
Reload if older than – You can specify the days, hours, mins, secs constant value to expire the data page.
Imagine you are using a data page to connect to different application to get security token. Business requirement will be like the security token is valid for only 8 hours. You need to request the application again to get a new security token after 8 hours.
Here we can create a data page D_Authorization, which can use connector as data source to get the security token.
You need to specify hours as 8 and leave other fields empty in refresh strategy.
So after 8 hours, this data page gets expired. So after 8 hours, if you refer the data page again, then data page gets refreshed with new data.
Refresh Strategy for thread/ requestor level data page
Reload once per Interaction – Checking this will allow data page to get loaded again and again when referred. This actually destroys the advantage of data page.
Important note: Reload once per interaction doesn’t meant it will load when referred in activity processing ( it is not interaction), only applicable based on User interactions.
Do not reload when – Specify a when rule.
When true – Use existing data page. No reload.
When false – Data page gets refreshed on subsequent access.
Page Limits – Clear pages after non-use
We know data page resides in clipboard even after expiration. Yes, it consumes space.
For node level
– You can check ‘clear pages’ after non-use to remove the data page from clipboard.
– DeclarePages/DefaultIdleTimeOut – DSS set to one day. After which the idle node level data pages gets removed.
– So after 1 day all the expired node level data pages get removed.
For requestor level
Requestors can open multiple threads (I can open multiple work items), so when a thread is requesting a requestor data page to get removed, then requestor level data page also gets removed.
3. Parameters tab
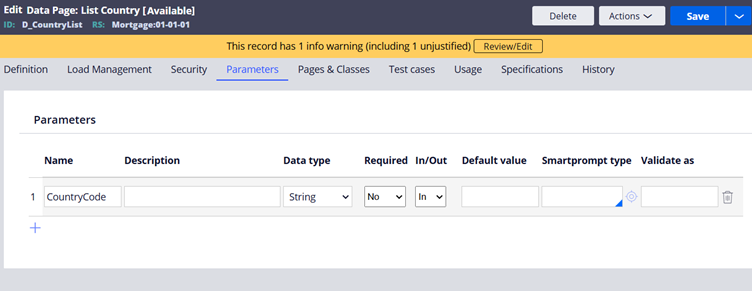
You can specify a parameter for a data page. For D_CountryList we can specify a CountryCode parameter.
This is more or less like a keyed page access. We can load the declare page with particular Country Code.
After specifying parameter, you can refer the data page like D_CountryList[“IND″] or D_CountryList[CountryCode:”IND”]
When you specify multiple parameters for the data page, specify all the parameters within square brackets when referred.
Also when you specify any parameters, make sure the parameter is passed on the Source configuration

When the parameterised data page is loaded, you can find the same in the clipboard with the right parameter.

Note: You can always run the data page manually by using the run button.
Where can we refer a data page?
Data pages can be referred in activity, data transform, sections table layouts, pagelist property referring to data pages.
How do we load a data page?
1. Whenever you refer the datapage for the first time in any of the above rules.
Let’s quickly implement it.
Step 1: In the Section configuration, you can use Picklist control and use Datapage as source.
Add a new field and defining data page source
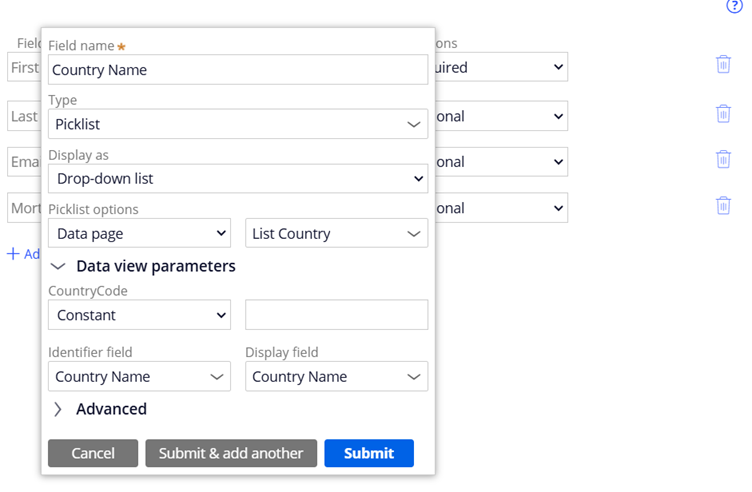
Step 2: Submit and test the data page loading part by creating a new case.

Step 3: Check the clipboard and you can find the list data page loaded with both the results.
2. In activity, you have a method ‘Load-Datapage’ to load the data page asynchronously.
What is asynchronous data page loading?
You can specify a data page to load asynchronously in an activity using Load-Datapage method.
Imagine the call center CRM application. When the agent engages with the customer through the phone, he needs to get the customer details before him. We may need to integrate it with other applications to get those data which can affect performance during loading.
Here, we may prefer loading the data asynchronously using data page.


When the Load-Datapage methods gets executed, the datapage gets loaded in background thread and the activity continues processing without waiting for data page loading.
You specify a pool ID for reference in load-datapage method.
After all your processing step in the activity, you can use Connect-Wait method at last referring the wait seconds and same pool ID we used in load-datapage method.
How do we remove a data page?
We already saw in the data page rule, you have an option to remove the data page.
Let me remind you one more thing. Pages in pega relate to Java Objects. Removing Java objects happens via Garbage collection.
You need to mark the Java objects to help the Garbage collector to remove the object.
So when you remove any page, not only data page, you basically mark the page for garbage collected (java object removal)
Let’s see what are the ways we can mark the data page to be removed
– In designer studio, you can open the data page rule and clear data page from load management tab.
– While using Page-Remove in activity steps, we can mark the data page to be removed. It is not recommended for node level data pages
– When node shuts down, all the data pages get removed, when the session or requestor timeout or log off, then all the thread level and requestor level data pages get removed..
– Always Use load management effectively to expire the data page at the appropriate time, so that it can be removed and reloaded later



